Le but de ce chapitre est de savoir résumer des données nombreuses et de savoir comment
trouver une relation entre deux variables.
Ce domaine est utile pour gérer des stocks, pour effectuer des contrôle de qualité, tout
comme l'évaluation de l'efficacité (d'un médicament ou autre), pour comprendre des
enquêtes.
Rappels sur les statistiques
Vocabulaire sur les statistiques
-
La population est l'ensemble observé par l'étude statistique.
-
Chaque élément de l'étude statistique (de la population donc) est appelé individu.
-
Le caractère est une propriété commune de la population étudiée.
-
Un échantillon est une partie de la population (complète) étudiée ; c'est un ensemble d'individus.
On considère l'ensemble des paquets reçus par un serveur sur une journée.
Pour estimer grossièrement la distance entre le client et le serveur, le Time To Live
de chaque paquet reçu est regardé.
Compléter chaque phrase suivante par les mots .
Écrire dans chacune des zones de textes un des mots suivants : la population, un individu,
le caractère ou un échantillon afin de définir chaque objet de l'étude statistique avant de cliquer sur ce bouton
.
-
Dans cette étude statistique, le Time To Live d'un paquet donné est appelée .
-
Dans cette étude statistique, un paquet particulier reçu est appelé .
-
Dans cette étude statistique, l'ensemble des paquets reçus par le serveur sur la journée est appelé .
-
Dans cette étude statistique, l'ensemble des paquets reçus par le serveur entre midi et 13 heure est appelé .
-
L'effectif d'une valeur d'un caractère est le nombre d'individus ayant cette valeur.
-
La fréquence d'une valeur d'un caractère est la proportion d'individus ayant cette valeur.
La fréquence est calculée par cette formule : $\dfrac{\text{effectif de la valeur}}{\text{effectif total}}$ ; c'est un nombre compris entre 0 et 1.
On considère l'ensemble des paquets reçus par un serveur sur une journée.
Pour estimer grossièrement la distance entre le client et le serveur, le Time To Live (TTL)
de chaque paquet reçu est regardé.
Hier, sur les 153207 paquets reçus sur la journée, 21491 avaient un TTL valant 63.
Saisir dans l'encadré suivant la fréquence des paquets ayant un TTL de 63 : .
Vérifier la réponse saisie en cliquant sur ce bouton .
Indicateurs de position centrale
On résume en général une étude statistique d'un caractère discret par un tableau à 2 ou 3 lignes :
| Valeur | $x_1$ | $x_2$ | ... | $x_k$ | ... | $x_p$ | Total |
|---|---|---|---|---|---|---|---|
| Effectif | $n_1$ | $n_2$ | ... | $n_k$ | ... | $n_p$ | $N$ | Fréquence | $f_1$ | $f_2$ | ... | $f_k$ | ... | $f_p$ | $1$ |
Dans ce tableau, il y a $p$ valeurs différentes prises par le caractère ; ces valeurs distinctes sont notées ici $x_1$,
$x_2$, ..., $x_p$.
Pour condenser l'information, on peut essayer de synthétiser l'ensemble des valeurs obtenues avec un seul nombre
qui donnera une idée de la "valeur centrale" du caractère.
Plusieurs indicateurs de position centrale existent, chacun ayant son intérêt.
Moyenne
La moyenne, souvent notée $\overline{x}$, d'une série statistique (réduite à un tableau comme ci-dessus) se calcule par la formule suivante : $\overline{x} = \dfrac{x_1\times n_1+x_2\times n_2+...+x_k\times n_k+...+x_p\times x_p}{n_1+n_2+...+n_k+...+n_p}$.
Pour éviter d'utiliser "...", en mathématique, on peut écrire les deux sommes précédentes avec le symbol $\Sigma$,
symbole lu "sigma" :
$ \overline{x} = \dfrac{\displaystyle \sum_{k=1}^{k=p}x_k\times n_k}{\displaystyle \sum_{k=1}^{k=p}n_k}$
Considérons que l'étude statistique mesurant les TTL (Time To Live) des paquets reçus par serveur sur une courte durée est résumé par le tableau suivant :
| TTL | 23 | 56 | 59 | 60 | 61 | 62 | 63 |
|---|---|---|---|---|---|---|---|
| Effectif | 1 | 3 | 4 | 2 | 5 | 7 | 6 |
Le TTL moyen (= la moyenne des valeurs mesurées pour le TTL) est : $\overline{x} = \dfrac{23\times 1+56\times 3 + 59\times 4 +60\times 2+61\times 5 +62\times 7+63\times 6}{1+3+4+2+5+7+6}=\dfrac{1664}{28}=\dfrac{416}{7}\approx 59.43$
Mode
Le mode d'une série statistique est la valeur la plus fréquente de cette série.
Considérons que l'étude statistique mesurant les TTL (Time To Live) des paquets reçus par serveur sur une courte durée est résumé par le tableau suivant :
| TTL | 23 | 56 | 59 | 60 | 61 | 62 | 63 |
|---|---|---|---|---|---|---|---|
| Effectif | 1 | 3 | 4 | 2 | 5 | 7 | 6 |
Le mode des valeurs du TTL est 62 car c'est la valeur la plus fréquente, celle à l'effectif le plus grand.
Médiane
La médiane, souvent notée $M_e$, d'une série statistique (réduite à un tableau comme ci-dessus) partage cette série en deux parties de telle sorte que :
-
Au moins la moitié des valeurs sont inférieures ou égales à la médiane ;
-
Au moins la moitié des valeurs sont supérieures ou égales à la médiane ;
Considérons que l'étude statistique mesurant les TTL (Time To Live) des paquets reçus par serveur sur une courte durée est résumé par le tableau suivant :
| TTL | 23 | 56 | 59 | 60 | 61 | 62 | 63 |
|---|---|---|---|---|---|---|---|
| Effectif | 1 | 3 | 4 | 2 | 5 | 7 | 6 |
Le TTL médian (= la médiane des valeurs du TTL) est 61.
En effet, il y a en tout 28 valeurs ; "50%" représente 14 valeurs.
Sur ces 28 données, 15 sont inférieures ou égales à 61 (1+3+4+2+5) : il y en a bien "au moins 50%".
Sur ces 28 données, 18 sont supérieures ou égales à 61 (5+7+6) : il y en a bien "au moins 50%".

La médiane découpe la série statistique en deux parties à peu près égales.
Il est possible de découper en plus de morceaux, d'où la notion suivante de quartile.
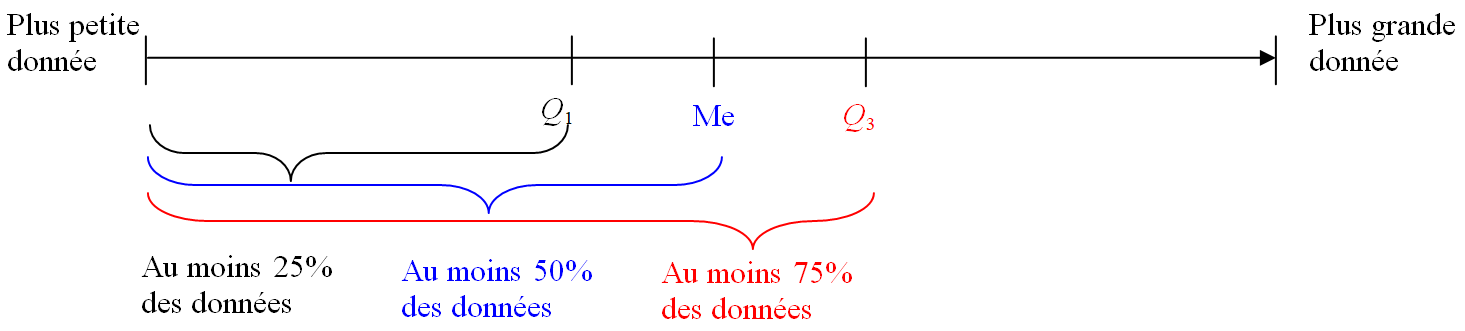
Quartile
On considère une série statistique dont les valeurs ont été rangées par ordre croissant.
-
Le premier quartile est la plus petite donnée $Q_1$ de la série triée telle qu'au moins un quart des données de la liste sont inférieures ou égales à $Q_1$.
-
Le troisième quartile est la plus petite donnée $Q_3$ de la série triée telle qu'au moins trois quarts des données de la liste sont inférieures ou égales à $Q_3$.
Considérons que l'étude statistique mesurant les TTL (Time To Live) des paquets reçus par serveur sur une courte durée est résumé par le tableau suivant :
| TTL | 23 | 56 | 59 | 60 | 61 | 62 | 63 |
|---|---|---|---|---|---|---|---|
| Effectif | 1 | 3 | 4 | 2 | 5 | 7 | 6 |
Il y a en tout 28 valeurs. 25% de 28 correspond à 7.
En tenant de compte des effectifs, la $7^{ème}$ donnée sera 59.
Le premier quartile est donc $Q_1=59$.
Il y a bien "au moins 25% dés valeurs inférieures ou égales à $Q_1$" car il y a 8 valeurs inférieures ou égales à $Q_1$ ici.
75% de 28 correspond à 21.
En tenant de compte des effectifs, la $21^{ème}$ donnée sera 62.
Le troisième quartile est donc $Q_3=62$.
Il y a bien "au moins 75% dés valeurs inférieures ou égales à $Q_3$" car il y a 22 valeurs inférieures ou égales à $Q_3$ ici.
On peut démontrer que cette définition des quartiles conduit au fait que l'on a découpé la série statistique en 4 parties, chacune contenant au moins 25% (=un quart) des données :
-
Entre le minimum et $Q_1$.
-
Entre $Q_1$ et $M_e$.
-
Entre $M_e$ et $Q_3$.
-
Entre $Q_3$ et la plus grande valeur de la série.
On peut aussi généraliser cette définition avec
-
Les déciles : le découpage se fait en 10 blocs chacun ayant au moins 10% des valeurs.
-
Les centiles : le découpage se fait en 100 blocs chacun ayant au moins 1% des valeurs.
Indicateurs de dispersion
Réduire un ensemble de données à un seul (ou quelques) indicateur de position centrale ne suffit
pas.
Par exemple, considérons deux groupes de 16 étudiant.e.s.
-
Dans le premier groupe, tous les étudiant.e.s ont obtenu 10 sur 20.
-
Dans le second groupe, la moitié a eu 0 et l'autre moitié 20.
Chacun des groupes obtient une moyenne et une médiane de 10. Pourtant l'hétérogénéité des deux groupes diffèrent au vu des résultats. Il faut prendre en compte d'autres types d'indicateurs, ceux qui mesurent une dispersion des valeurs par rapport au position centrale.
Étendue
L'étendue d'une série statistique est l'écart entre la valeur maximale de la série avec la valeur minimale.
Considérons que l'étude statistique mesurant les TTL (Time To Live) des paquets reçus par serveur sur une courte durée est résumé par le tableau suivant :
| TTL | 23 | 56 | 59 | 60 | 61 | 62 | 63 |
|---|---|---|---|---|---|---|---|
| Effectif | 1 | 3 | 4 | 2 | 5 | 7 | 6 |
La valeur maximale du TTL est $63$ ; celle minimale est $23$.
L'étendue est donc de $40 (=63-23)$.
Variance et écart-type
La variance d'une série statistique est la moyenne arithmétique des carrés des écarts entre chaque valeur et la moyenne de la série.
Pour une série statistique synthétisée dans le tableau suivant
| Valeur | $x_1$ | $x_2$ | ... | $x_k$ | ... | $x_p$ | Total |
|---|---|---|---|---|---|---|---|
| Effectif | $n_1$ | $n_2$ | ... | $n_k$ | ... | $n_p$ | $N$ |
La variance est obtenue par la formule suivante : $V(x)=\displaystyle \dfrac{1}{N}\sum_{k=1}^{k=p}n_k \times (x_k-\overline{x})^2$.
La variance est égale à l'écart entre la moyenne des carrés des valeurs avec la carré de la moyenne des valeurs : $V(x)=\overline{x^2}-\overline{x}^2$.
Le problème de la variance est le sens à donner à l'unité concrète du nombre obtenu.
Supposons que les valeurs de la série statistique considérée correspondent à des sommes d'argent
exprimées en $€$.
Le nombre issu du calcul de la variance correspondra alors à des $€^2$. Quel est le sens
d'un $€^2$ ?
Pour éviter ce problème d'unité, on définit la notion d'écart-type, qui a elle la même unité que chaque valeur de la série.
L'écart-type d'une série statistique est la racine carrée de la variance : $\sigma(x)=\sqrt{V(x)}$.
L'écart-type $\sigma(x)$ se lit "sigma de x".
Considérons que l'étude statistique mesurant les TTL (Time To Live) des paquets reçus par serveur sur une courte durée est résumé par le tableau suivant :
| TTL | 23 | 56 | 59 | 60 | 61 | 62 | 63 |
|---|---|---|---|---|---|---|---|
| Effectif | 1 | 3 | 4 | 2 | 5 | 7 | 6 |
Nous avions déjà calculé le TTL moyen (= la moyenne des valeurs mesurées pour le TTL) est : $\overline{x} = \dfrac{23\times 1+56\times 3 + 59\times 4 +60\times 2+61\times 5 +62\times 7+63\times 6}{1+3+4+2+5+7+6}=\dfrac{1664}{28}=\dfrac{416}{7}\approx 59.43$.
La variance est donnée par ce calcul : $V(x) = \dfrac{1}{28}\times \left(1\times \left(23-\dfrac{416}{7}\right)^2+3\times \left(56-\dfrac{416}{7}\right)^2 + 4\times \left(59-\dfrac{416}{7}\right)^2 +2\times \left(60-\dfrac{416}{7}\right)^2 \right.$ $\quad\quad\quad\left. +5\times \left(61-\dfrac{416}{7}\right)^2+7\times \left(62-\dfrac{416}{7}\right)^2+6\times \left(63-\dfrac{416}{7}\right)^2\right)$ $=\dfrac{2623}{49}\approx 53.53$.
L'écart-type est donné par : $\sigma(x)=\sqrt{V(x)}=\sqrt{\dfrac{2623}{49}}=\dfrac{2623}{7}\approx 7.31646$.
Concrètement cela signifie que si le TTL vaut en moyenne 59.43, la "dispersion moyenne" des TTL des paquets par rapport à cette moyenne est d'environ 7.3.
Écart interquartile
L'écart interquartile est l'écart entre le troisième quartile et le premier : $Q_3-Q_1$.
Considérons que l'étude statistique mesurant les TTL (Time To Live) des paquets reçus par serveur sur une courte durée est résumé par le tableau suivant :
| TTL | 23 | 56 | 59 | 60 | 61 | 62 | 63 |
|---|---|---|---|---|---|---|---|
| Effectif | 1 | 3 | 4 | 2 | 5 | 7 | 6 |
Nous avions déjà montré que le premier quartile de cette série est $Q_1=59$
et que le troisième quartile est $Q_3=62$.
L'écart interquartile est donc de 3 (car $62-59=3$).
Concrètement, cela signifie que plus de la moitié des valeurs (celles les plus centrales
se trouvant entre $Q_1$ et $Q_3$) sont dispersées d'au plus 3.
Il existe d'autres indicateurs de dispersion.
Par exemple, l'écart interdécile $D_9-D_1$ est très utilisé en économie par exemple
pour estimer les inégalités de revenus. $D_9$ correspond au revenu de la personne telle que 90% des
personnes ont un revenu inférieur ou égal à elle (c'est la personne ayant le moins de revenu
parmi les 10% ayant les plus hauts revenus) tandis que $D_1$ correspond au revenu de la personne
telle que 10% des personnes ont un revenu inférieur ou égal à elle (c'est la personne ayant le plus
haut revenu parmi les 10% ayant les revenus le plus bas).
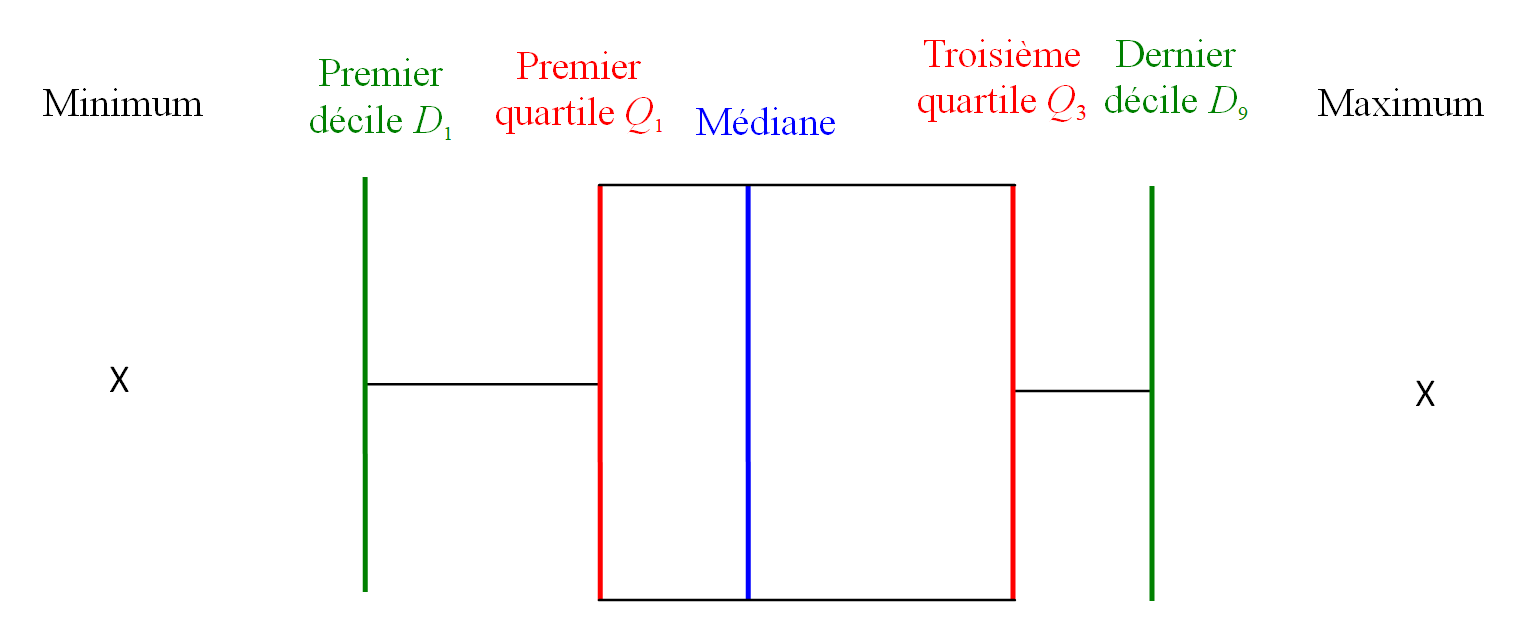
Boîte à moustaches
Une boîte à moustaches est une manière de représenter graphiquement les différents indicateurs de position centrale :
-
Le minimum et le maximum comme "poils isolés" à l'extérieur de la "moustache".
-
Les déciles $D_1$ et $D_9$ comme limites de la moustache.
-
Les quartiles $Q_1$ et $Q_3$ comme limites de la partie centrale de la "moustache".
-
La médiane $M_e$ comme trait vertical dans la partie centrale de la "moustache".
Considérons que l'étude statistique mesurant les TTL (Time To Live) des paquets reçus par serveur sur une courte durée est résumé par le tableau suivant :
| TTL | 23 | 56 | 59 | 60 | 61 | 62 | 63 |
|---|---|---|---|---|---|---|---|
| Effectif | 1 | 3 | 4 | 2 | 5 | 7 | 6 |
Le premier décile $D_1$ de la série vaut 56 (car au moins 10% des valeurs sont inférieures ou égales à 56 et au moins 90% des valeurs sont supérieures ou égales à 56).
Le dernier décile $D_9$ de la série vaut 63 (car au moins 90% des valeurs sont inférieures ou égales à 63 et au moins 90% des valeurs sont supérieures ou égales à 63).
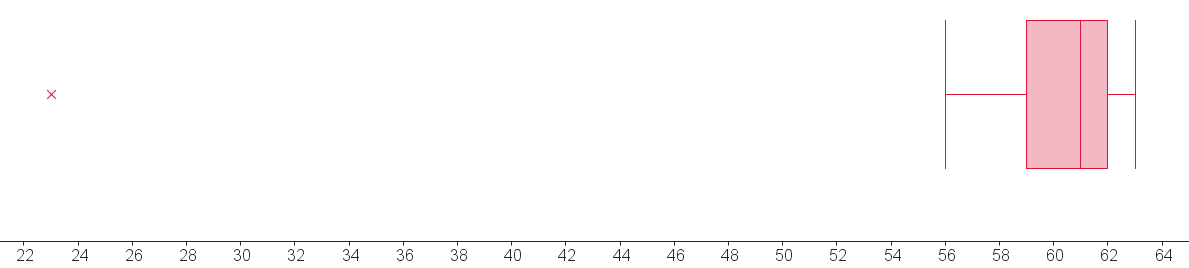
L'ensemble des données déjà calculées 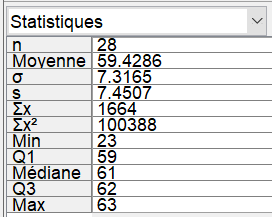 peuvent être résumées par la boîte à moustache suivante :
peuvent être résumées par la boîte à moustache suivante :
Un assembleur d'ordinateurs portables hésitent entre deux types de batteries :
-
Batteries lithium ion.
-
Batteries lithium polymère.
Lors de tests, différents nombres de cycles de charge/décharge de batteries ont été mesurés.
L'ensemble des données ont été résumées dans les deux boîtes à moustaches suivantes :

-
Pour chaque type de batteries, déterminer graphiquement la valeur de toutes les caractéristiques statistiques de position centrale visibles.
-
Quelle est la proportion de batteries lithium ion ayant duré au plus 500 cycles de charges/décharges dans le test ?
Même question pour les batteries lithium polymère. -
Quelle est la proportion de batteries lithium ion ayant duré entre 500 et 800 cycles de charges/décharges dans le test ?
Même question pour les batteries lithium polymère. -
En supposant que les tests réalisés soient représentatifs des batteries de chaque type, quel type de batteries est à préférer pour avoir une durée de vie de la batterie plus importante ?
Justifier en utilisant des caractéristiques de position centrale ou de dispersion. -
Un client a une politique de renouvellement complet de son parc d'ordinateurs portables au bout d'un certain temps afin que l'ensemble des collaborateurs travaillent toujours sur le même type d'ordinateurs. Ce client achète une proportion supplémentaire d'ordinateurs à ce qui lui est initialement nécessaire afin de gérer un accroissement du nombre d'employé.e.s et d'éventuelles pannes.
C'est pourquoi le client veut une dispersion minimale dans la durée de vie du lot d'ordinateurs achetés.
Quel type de batteries conviendrait davantage à ce client ?
Justifier en utilisant des caractéristiques de position centrale ou de dispersion.
Utilisation de Geogebra
En BTS, il vous sera demandé de savoir obtenir les indicateurs de position centrale et de dispersion grâce à un logiciel puis de savoir les interpréter pour répondre à des questions concrètes.
Comme pour les probabilités, le logiciel qui sera à utiliser sera Geogebra.
Voici les étapes à suivre pour obtenir les indicateurs statistiques sur Geogebra :
-
Saisie des valeurs
Dans la partie tableur (lancée à partir de ), saisir
les données par colonne.
), saisir
les données par colonne.
Pour accéder au tableur, aller dans Affichage > Tableur :
-
Sélection des données
Sélectionner la colonne donnant les différentes valeurs puis "Statistiques à une variable" en cliquant sur l'icône .
.
Dans la fenêtre qui s'ouvre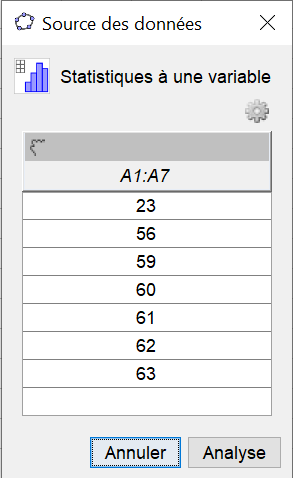 ,
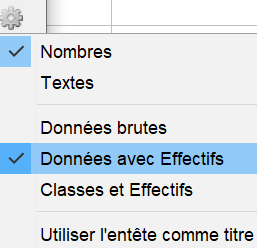
cliquer sur l'engrenage afin de sélectionner "Données avec Effectifs":
,
cliquer sur l'engrenage afin de sélectionner "Données avec Effectifs":
Sélectionner la colonne contenant les effectifs, puis cliquer sur la main à côté du mot "Effectifs" : .
.
En cliquant sur "Analyse"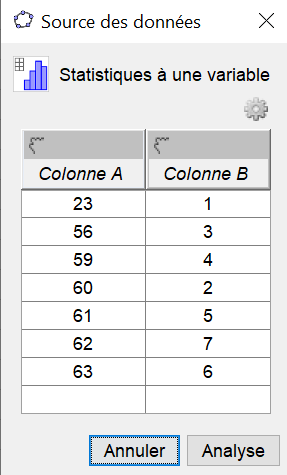 ,
vous allez faire apparaître une zone "Analyse des données" où apparaissent les valeurs en abscisses et leur effectif
en ordonnée dans un diagramme en barres :
,
vous allez faire apparaître une zone "Analyse des données" où apparaissent les valeurs en abscisses et leur effectif
en ordonnée dans un diagramme en barres :

-
Obtention des indicateurs statistiques
Cliquer sur l'icône afin d'obtenir la valeur approchée des indicateurs statistiques :
.
afin d'obtenir la valeur approchée des indicateurs statistiques :
.
On retrouve dans les indicateurs statistiques affichés dans la méthode précédente, les valeurs
approchées trouvées dans les exemples de la partie I.
:
-
$n$ donne l'effectif total, ici 28.
-
$Moyenne$ donne une valeur approchée de la moyenne.
-
$\sigma$ donne une valeur approchée de l'écart-type.
-
$Min$ donne le minimum de la série.
-
$Q_1$ donne le premier quartile de la série.
-
$Médiane$ donne une valeur approchée de la médiane.
-
$Q_3$ donne le troisième quartile de la série.
-
$Max$ donne le maximum de la série.
Le but de cet exercice est de comprendre l'influence d'une valeur aberrante sur certains indicateurs.
L'étude statistique mesurant les TTL (Time To Live) des paquets reçus par serveur à un moment sur une courte durée est résumé par le tableau suivant :
| TTL | 23 | 56 | 59 | 60 | 61 | 62 | 63 |
|---|---|---|---|---|---|---|---|
| Effectif | 1 | 3 | 4 | 2 | 5 | 7 | 6 |
Ces données ont déjà été traités précédemment ; on a obtenu les indicateurs suivants :
.
La valeur 23 semble être aberrante car elle diffère de toutes les autres valeurs obtenues.
-
Déterminer les caractéristiques statistiques pour le tableau statistiques dans lequel est ôté la valeur aberrante 23 :
TTL 56 59 60 61 62 63 Effectif 3 4 2 5 7 6 -
En comparant les deux séries statistiques, déterminer quels sont les indicateurs de position centrale et de dispersion qui sont sensibles à la valeur aberrante 23.
En économie, on considère deux principaux types de position centrale des revenus :
-
Le revenu moyen qui correspond à la moyenne des revenus obtenus dans l'ensemble de la population.
-
Le revenu médian qui correspond à la médiane des revenus obtenus dans l'ensemble de la population.
Comme le revenu moyen est impacté à la hausse par les plus hauts revenus, celui qui est
surtout significatif est celui de revenu médian.
En France, en 2018, le revenu (disponible) moyen par habitant s'établissait aux alentours de 2054€ par mois
tandis que le revenu (disponible) médian était d'environ 1771€.
(source : INSEE )
Le revenu médian sert à définir en économie le niveau de seuil de pauvreté.
Un serveur reçoit des paquets venant à la fois d'un réseau interne et est aussi connecté au réseau
Internet.
On compare les TTL reçus par le serveur à deux moments assez courts : $moment 1$ et $moment 2$.
On rappelle que le TTl signifie Time To Live : il correspond à un nombre initialisé (le plus souvent) à
64 lors de l'envoi du paquet et qui diminue de 1 à chaque passage du paquet par un routeur.
Voici les données collectées :
L'étude statistique mesurant les TTL (Time To Live) des paquets reçus par serveur au $moment 1$ sur une courte durée est résumé par le tableau suivant :
| TTL | 23 | 56 | 59 | 60 | 61 | 62 | 63 |
|---|---|---|---|---|---|---|---|
| Effectif | 1 | 3 | 4 | 2 | 5 | 7 | 6 |
Ces données ont déjà été traités précédemment ; on a obtenu les indicateurs suivants :
.
L'étude statistique mesurant les TTL (Time To Live) des paquets reçus par serveur au $moment 2$ sur une courte durée est résumé par le tableau suivant :
| TTL | 49 | 56 | 57 | 58 | 59 | 60 | 61 | 62 | 63 |
|---|---|---|---|---|---|---|---|---|---|
| Effectifs | 1 | 5 | 7 | 8 | 9 | 5 | 8 | 7 | 9 |
-
Déterminer les caractéristiques statistiques liées au données mesurées au $moment 2$.
-
En comparant les deux séries statistiques, déterminer à quel moment, le serveur a davantage reçu des paquets venant du réseau Internet et non du réseau interne.
Justifiez votre affirmation en utilisant des indicateurs de position centrale et de dispersion.
Le diagramme en boîte ci-dessous synthétise le nombre de naissances, en milliers par an, en France
métropolitaine entre 1901 et 1920.

-
Lire et donner la médiane, les premier et troisième quartiles, les premier et dernier décile ainsi que les valeurs extrêmes.
-
Est-il vrai qu'entre 1901 et 1920, le nombre annuel de naissances a atteint ou dépassé 630 milliers au moins 15 années ?
Justifier à l'aide d'un indicateur de position centrale ou de dispersion. -
Est-il vrai qu'entre 1901 et 1920, le nombre annuel de naissances a été compris entre 825000 et 900000 durant 9 années ?
Justifier à l'aide d'un indicateur de position centrale ou de dispersion.
Ce fichier Geogebra à télécharger contient le nombre de naissances, en milliers
par an, en France métropolitaine entre 1982 et 2022, sachant que Mayotte est prise en compte depuis 2014.
(source : INSEE )
-
Déterminer les caractéristiques de position centrale et de dispersion de cette série.
-
Est-il vrai que l'intervalle interquartile était plus de 5 fois plus grand entre 1901 et 1920 qu'entre 1982 et 2022 ?
Justifier. -
Quelle est la proportion du nombre d'années où il y a eu entre 825 et 875 milliers de naissances entre 1901 et 1920 ? Justifier.
Même question entre 1982 et 2022. -
Est-il vrai que l'on peut savoir en comparant les données si le nombre de naissances était en moyenne plus grand entre 1901 et 1920 qu'entre 1982 et 2022 ?
L'observation des inégalités est un organisme d'information indépendant qui dresse un état des lieux des inégalités à partir de données publiques. Cet organisme est composé surtout de sociologues et d'économistes.
Accéder à cette page site de l'observatoire des inégalités qui permet de positionner son salaire par rapport à l'ensemble des salarié.e.s en France en 2024.
-
Dans la zone de saisie de salaires, écrire 1746 puis appuyer sur "GO !" afin de déterminer le pourcentage de personnes ayant un salaire inférieur à 1746€.
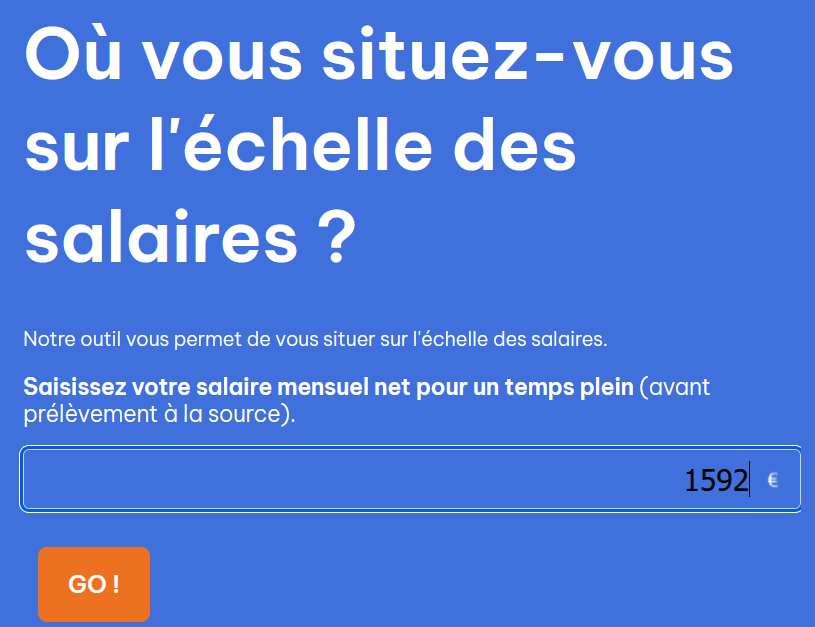
Quel indicateur de position centrale ou de dispersion a pour valeur 1746 ? -
Vérifier que 10% des salariés touchaient moins de 1492€ par mois (en 2024).
-
Déterminer la médiane, le troisième quartile et le dernier décile des salaires en France en 2024.
-
En 2024, les salariés du secteur privé gagnent en moyenne 2 730 euros net par mois en équivalent temps plein (c’est-à-dire pour un volume de travail correspondant à un temps complet) d'aprèsd'après le rapport de janvier 2026 de l'INSEE. Déterminer la proportion des personnes qui touchaient moins que la salaire moyen en 2024.
Comment pouvez-vous concrètement expliquer le fait que ce pourcentage est assez loin du 50% attaché au salaire médian ?
Vous pouvez voir sur ce site qu'en 2024 le salaire brut médian d'un jeune diplômé d'un bac +2 était de 28 000 euros alors que celui d'un jeune diplômé d'un bac +3/4 était en moyenne de 37 000 euros (sans mentionner les 42 500€ d'un bac +5).
Ainsi, penser à poursuivre ses études après le BTS CIEL peut être fortement judicieux ! Pensez-y dès maintenant !
Voici un test de deux questions portant sur les statistiques descriptives.
Demander le programme
-
Le vocabulaire sur les statistiques (population, individu, caractère, échantillon, effectif, fréquence).
-
La formule définissant la moyenne, de la médiane et du mode.
-
La définition de la médiane et du mode.
-
Savoir que la moyenne, la médiane et le mode sont des indicateurs de position centrale.
-
La définition des quartiles.
-
La définition de l'étendue, de la variance, de l'écart-type et de l'écart interquartile.
-
Savoir que l'étendue, de la variance, de l'écart-type et de l'écart interquartile sont des indicateurs de dispersion de la série statistique.
-
Savoir calculer la fréquence d'un caractère à partir de son effectif.
-
Savoir lire les valeurs d'une boîte à moustaches.
-
Savoir utiliser Geogebra afin d'obtenir les indicateurs de position centrale et de dispersion.
-
Savoir utiliser Geogebra afin d'obtenir un diagramme représentant une série statistiques (diagramme en barres, boite à moustaches).
-
Savoir comparer des séries statistiques à l'aide des indicateurs de position centrale et/ou de dispersion.

Les différents
auteurs mettent l'ensemble du site à disposition selon les termes de la licence Creative
Commons Attribution - Pas d’Utilisation Commerciale - Partage dans les Mêmes Conditions 4.0
International