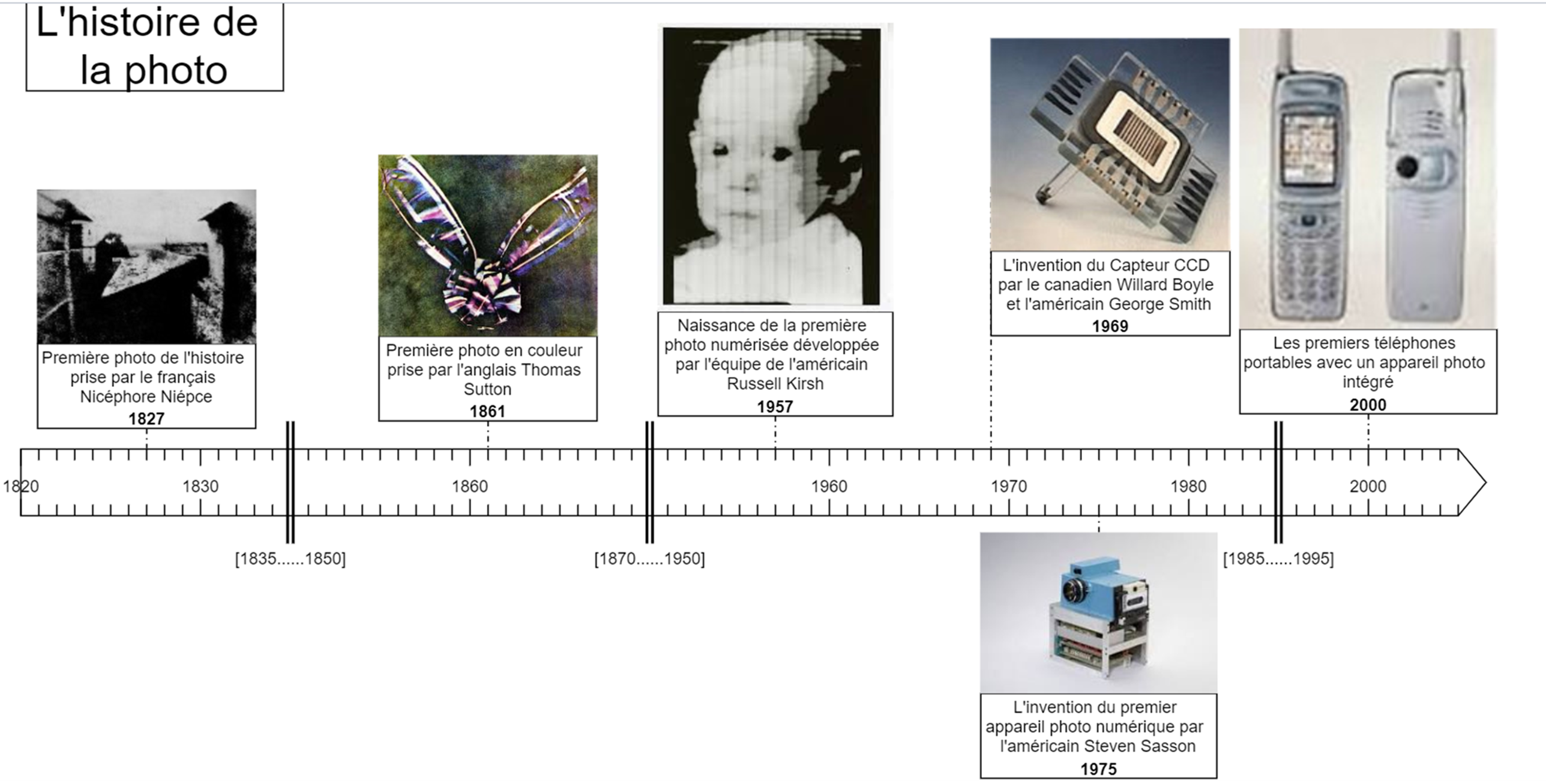
Ci-dessus quelques repères historiques de la photo numérique présentés sous la forme d'une frise :
Au cours de ce thème vous aurez à utilisez le logiciel GIMP, logiciel libre
et gratuit qui vous permettra de
visualiser des images et surtout de les retoucher.
Il est normalement déjà installé sur vos ordinateurs prétés par la Région Grand-Est.
Si cela n'est pas le cas, pour installer GIMP, il vous suffit de suivre le tutoriel présent
dans le document téléchargeable ici.
La version de GIMP la plus récente est la 2.10.30 et non plus celle du tutoriel mais la démarche à suivre reste strictement la même.
Partie 1 : L'oeil et le capteur numérique
L'oeil et le capteur photographique
1.1.1 La vision humaineLes rayons lumineux provenant d'un objet sont projetés au fond de l'oeil sur la rétine. |
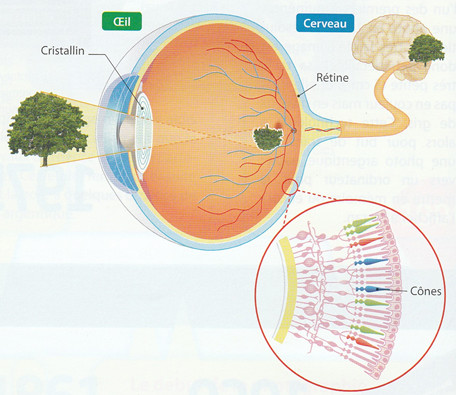 |
1.1.2 L'appareil photo numériqueLes rayons lumineux provenant d'un objet sont projetés dans l'appareil photo sur le capteur photographique. Celui-ci est constitué de cellules sensibles à la lumière. La mesure de l'intensité lumineuse est transformée en données numériques puis stockée dans la mémoire de l'appareil. |
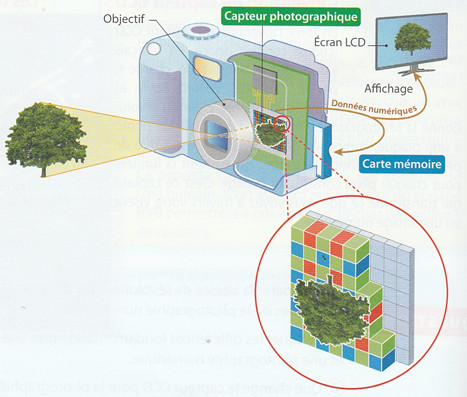 |
1.1.3 Le fonctionnement du capteur photographiqueLes capteurs photographiques sont des éléments électroniques sensibles à la lumière, qui produisent des électrons (de l'électricité) lorsqu'ils reçoivent des photons (de la lumière). Un capteur d'appareil photo numérique est composé de cellules photosensibles : les photosites. Pour que ceux-ci distinguent les couleurs, chacun est placé derrière un filtre qui ne laisse passer que les rayons d'une seul couleur : rouge, vert ou bleu (2 verts, 1 rouge et un bleu par carré). Les photosites mesurent ainsi l'intensité lumineuse des rayons rouges (R), des rayons verts (V) et des rayons bleus (B). La tension électrique produite est ensuite convertie en nombre et envoyée au processeur de l'appareil photo. La définition d'un capteur est le nombre total de ses photosites. |
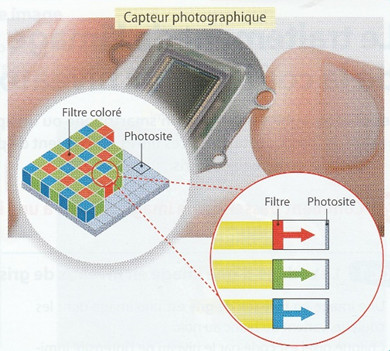 |
| Source des images : SNT 2de, Sciences numériques et Technologie, pages 106-107, édition Delagrave, Paris 2019. |
-
En comparant les images schématisant la vision humaine et l'appareil photo numérique, quel est l'équivalent au niveau de l'appareil numérique :
-
du cristallin de l'oeil humain ?
-
de la rétine de l'oeil ?
-
du cerveau humain ?
-
d'un cône ?
-
-
Où se situe le capteur d'un appareil photo ?
-
Pourquoi mettre sur un capteur photographique deux fois plus de photosites sensibles à la couleur verte qu'aux deux autres couleurs ?
-
Que représente la définition d'un capteur photo ?
-
Quels sont les principaux éléments d'un appareils photos ? Résumer son principe de fonctionnement.
Notion d'image numérique
Une image numérique est constituée d’un ensemble de pixels, c’est-à-dire de
petits carrés colorés
disposés les uns à côté des autres sous la forme d'un tableau à deux dimensions, le pixel représente
ainsi le plus
petit élément constitutif d'une image numérique.
Chaque pixel est caractérisé par sa position sur l’image (sous forme de coordonnées), et sa couleur.
Définition d'une image
La définition d’une image numérique est le nombre de pixels qui la composent.
si par exemple les dimensions de l’image sont 300 pixels en largeur et 200 pixels en hauteur, sa définition sera de 60 000 pixels ($60 000 = 200\times 300$).
On parle aussi de définition lorsqu’on veut exprimer la qualité d’un appareil photographique : si un
fabricant
annonce que son appareil a 18 mégapixels (soit 18 millions de pixels), cela signifie qu’il prend des
photographies
dont les dimensions sont $5184 \times 3456$ pixels.
Cependant en pratique, il est bien difficile de
distinguer
une
photo à 18 mégapixels d’une autre à 12 mégapixels.
Résolution d'une image
La résolution d’une image est exprimée par un nombre de pixels par unité de longueur (souvent le pouce, soit 2,54 centimètres).
Il est utile de l’évoquer lorsqu’on affiche une image sur un écran ou qu’on l’imprime sur papier : habituellement, les écrans d’ordinateurs ont une résolution de 72 pixels/pouce (soit environ 28 pixels/centimètre), alors que les impressions sur papier requièrent une résolution de 300 pixels/pouce.
-
On dispose d’une image de dimensions 75×50 pixels, et on l’imprime sur une feuille de dimensions 15×10 centimètres. Quelle sera la taille de chaque pixel imprimé ? Que peut-on craindre du résultat ?
-
Quelles devraient être les dimensions de la feuille si on souhaite réaliser une impression avec une résolution de 100 pixels/pouce?
-
On souhaite imprimer une image sur une feuille de dimensions 15×10 centimètres. Quelles devraient être les dimensions de l’image (en pixels) si on souhaite obtenir une résolution de 300 pixels par pouce ?
Profondeur de couleur
La profondeur de couleurs, dont l'unité est le "bits par pixel" (bpp),
correspond au nombre de bits (c'est-à-dire
de 0 et de 1) nécessaire pour stocker en mémoire la couleur d'un pixel.
Plus la profondeur de couleurs est
grande plus l'échelle de nuances des couleurs est grande
et plus la qualité de l'image est meilleure.
Voici la même photographie a été stockée en tant que trois images ayant une profondeur de couleurs différents :
-
l'une a été enregistrée avec 4 bpp, c'est à dire avec seulement 16 couleurs possibles,
-
une autre avec 8 bpp, c'est à dire avec 256 couleurs possibles,
-
enfin la dernière avec 24 bpp, c'est à dire avec environ 16 millions de couleurs possibles.
|
Image 1 : |

|
|
Image 2 : |

|
|
Image 3 : |

|
Associer à chacune des images ci-dessus sa profondeur.
Vous pouvez regarder entre autre le centre de l'allée pour différencier certains cas.
Le poids d'une image
Le poids d'une image est la mémoire nécessaire à son enregistrement, il est mesuré en kilooctets, notés ko, ou en mégaoctets, notés Mo.
-
Dans un appareil photo numérique, quel réglage permet d'obtenir des photos de meilleure qualité ?
-
Que représentent la définition du capteur et la définition d'une photo ? Le nombre de pixels de la photo est-il nécessairement égal au nombre de photosites du capteur ?
-
Comment évolue le poids d'une image si :
-
la définition de l'image augmente ?
-
la résolution de l'image augmente ?
-
la profondeur des couleurs de l'image augmente ?
-
Les métadonnées EXIF
Dans les appareils numériques, les métadonnées sont automatiquement inscrites et enregistrées dans le fichier image. L'ensemble de ces informations est appelé métadonnées EXIF, EXIF pour Exchangeable Image File Format (signification en français : "format d'échange de données pour les fichiers images" ).
Il est possible d’obtenir simplement les caractéristiques d’une image. Dans l’explorateur Windows, un clic droit sur le fichier image permet d’accéder à ses propriétés. Dans l’onglet Général, on trouve entre autres :
- le nom du fichier ;
- le type (ou format) du fichier (par exemple JPG) ;
- son emplacement dans la mémoire de l’ordinateur ;
- sa définition.
Dans l’onglet Détails, on trouve aussi :
- ses dimensions;
- sa résolution.
- Les coordonnées GPS précises du lieu où a été prise l'image, etc ...

-
Afficher les métadonnées EXIF de cette image en utilisant l'explorateur Windows.
-
Quelle est la définition de cette image ?
-
Quel est son poids ?
-
Quelles devraient être les dimensions de la feuille d'impression de cette image si on souhaite l'imprimer avec une résolution de 300 pixels/pouce ?
-
Quelle est la valeur de la profondeur en couleur de cette image ? Que signifie cette valeur ?
-
Déterminer les données permettant de déterminer la position du lieu où a été prise cette image.
-
À l'aide de ces données, déterminer le lieu où a été prise l'image.
Faire une recherche sur Qwant pour trouver un site qui permet de localiser un lieu à partir de ses coordonnées GPS.
Dans le dossier "SNT_2020-21", créer un dossier nommé "Photographie" que nous allons utiliser pour le thème photographie. Dans le dossier "Photographie" créer un dossier et appeler le "Activite1"
Un internaute vient de publier sur une page Web deux photos :
 |

|
Le but est de localiser le trésor !
-
Télécharger les deux images ci-dessous à l'aide d'un clic droit pour les mettre dans le même répertoire que celui de l'exercice précédent.
-
Etudier les métadonnées Exif disponibles sur la première photo. Quelles informations obtient-on sur l'image ?
-
Etudier les métadonnées Exif disponibles sur la seconde photo. Quelle information obtient-on sur le lieu où a été pris la photo ?
-
Outre les données directement accessibles depuis les propriétés du fichier image, d’autres métadonnées sont disponibles. Certains sites (ou logiciels) permettent d’extraire d’un fichier les métadonnées qu’il contient.
Par exemple, utiliser le site https://www.get-metadata.com/ pour extraire de nouvelles informations sur la localisation du trésor. -
Localiser le lieu où le trésor est caché.
Pour protéger vos données personnelles, vous devez les supprimer avant de les envoyer ou de les publier sur un réseau social.
-
Pour chacune des images téléchargées de l'exercice précédent, ouvrir les propriétés de l'image et supprimer les propriétés et les informations personnelles par un clic judicieux.
-
Peut-on encore localiser le trésor à partir des données restantes ?
Pour effacer les métadonnées EXIF sur un smartphone, vous pouvez suivre les procédures proposées à cette adresse.
Lorsque vous publiez des photos sur des réseaux sociaux, des données personnelles peuvent être transmises si vous
n'y prenez pas garde.
Le 5 septembre 2022, Instagram, filiale du groupe Meta (nouveau nom de Facebook) a été condamné dans l'Union
Européenne à une amende de 405 millions d'euros pour ne pas protéger suffisamment les données des mineurs.
Cette décision a été permise par la mise en place du Réglement Général sur la Prtotection de Données (RGPD), réglement
européen qui permet de protéger les citoyens européens dans le monde numérique.
Le groupe américain a fait appel de cette décision.
Les images proposées ci-dessus sont « libres de droits ».
Rechercher la signification de cette expression.
Vous pouvez approfondir la notion de "librs de droit" en cherchant à comprendre les licences Creative Commons.
 (image de Simon Villeneuve)
(image de Simon Villeneuve)
Si vous avez apprécié le fait d'essayer de localiser une photographie, sachez qu'il existe un collectif
sur twitter qui propose d'apprendre aux utilisateurs de nouvelles techniques de vérification des images
en ligne.
Il suffit que les joueurs retrouvent l'endroit où a été pris la photo à partir d’indices présents dans
la photo.
Attention ! Il ne suffit pas de se contenter de trouver des métadonnées dans ce jeu mais de repérer
des
indices visuels et d'effectuer des recherches sur Internet.
Chaque participant explique la démarche qui lui a permis de localiser la photo du jour : ainsi, au fil des résolutions, on apprend à trouver des indices et à les utiliser de manière performante !
Si vous voulez devenir des Sherlock Holmes du XXIè siècle, n'hésitez pas !
Comme de plus, de nombreux posts sont en anglais, vous vous améliorerez aussi dans la langue de Sherlock Holmes !
Voici une page web contenant une vidéo qui présente le jeu et explicite une résolution particulière. (vous y apprendrez en particulier comment faire pour retrouver une photo en taille originale pour pouvoir y trouver des indices.
Voici le lien pour accéder au collectif quiztime sur Twitter.
En que que citoyens, il est important de savoir que les vidéos aussi possèdent des métadonnées. Leurs analyses peuvent apporter des informations essentielles.
Voici deux exemples de vidéos, en lien avec la guerre en Ukraine, où l'analyse des métadonnées permettent de savoir si la date indiquée de tournage est la réelle date ou pas. Cette information a des conséquences dans l'interprétation géopolitique de ces vidéos.
-
Le 18 janvier 2022, le chef de l'autoproclamée république populaire de Donetsk (région officiellement ukrainienne) publie une vidéo dénonçant le début de bombardements ukrainiens et annonçant une évacuation massive et ordonnée de la population vers la Russie à partir de ce jour du 18 janvier.
Or, cette vidéo postée sur le réseau social Telegram a conservée ses métadonnées : elles indiquent que la vidéo a été réalisée le 16 janvier 2022, soit avant le début des bombardements dénoncés par ce dirigeant.
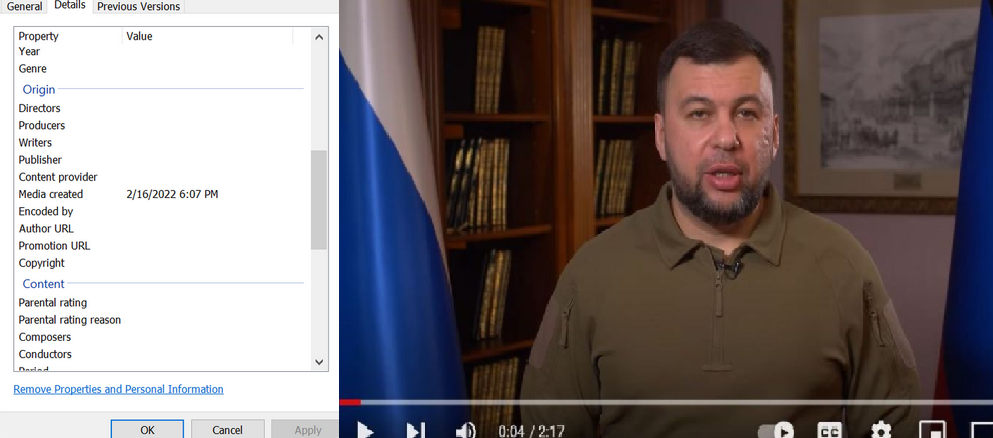 Voici un accès direct à la vidéo sur Telegram.
Voici un accès direct à la vidéo sur Telegram.
Initialement révélées lors d'un tweet par un journaliste du site d'investigation journalistique bellingcat.com, cette information a été vérifiée par différents autres journalistes depuis.
Vous pouvez entre autre vérifier ces affirmations sur cette page d'information en français ou celle-ci en anglais -
Le 24 février 2022, le président russe Vladimir Poutine annonce dans une vidéo le début de l'invasion de l'Ukraine par les troupes russes. Cette vidéo est disponible sur le site officiel du Kremlin.
Le 21 février 2022, le président russe avait déjà annoncé dans une autre vidéo la reconnaissance des états autoproclamés de Louhansk et de Donetsk, deux régions adminstrées officiellement par l'Ukraine.
Des personnes ont remarqué que le président portait exactement les mêmes habits sur les deux vidéos et que des éléments visibles sur les vidéos étaient identiques (position des papiers en arrière-plan, position du cordon téléphonique, ...). Ces personnes ont en déduit que les deux vidéos avaient été filmées surement le même jour mais diffusées à deux dates différentes.
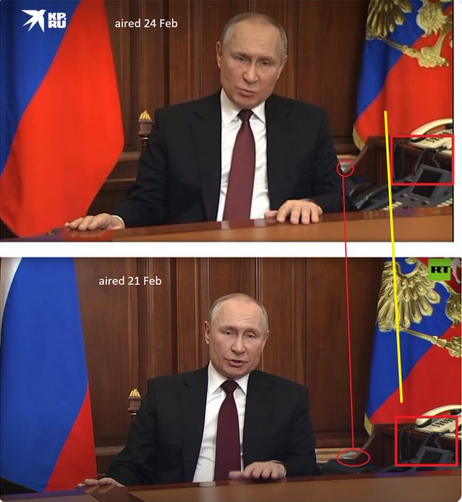 accès au compte Tweeter source
accès au compte Tweeter source
Le journal Novaya Gazeta (qui est resté jusque fin mars 2022 ledernier journal indépendant russe, journal dont le rédacteur en chef a obtenu le prix Nobel de la Paix en 2021) a publié le 25 février 2022 un article dans lequel il affirmait que certains de ses journalistes ont analysé les métadonnées de la vidéo publié le 24 février et que celles-ci indiquées une date de création du 21 février. D'autres journalistes ont vérifié cette information et ont montré que finalement les métadonnées date bien la vidéo du 24 février. Le journal Novaya Gazeta a depuis officiellement reconnu l'erreur dans l'analyse des données.
Cependant, il est assez simple de créer un programme informatique pour modifier arbitrairement des métadonnées. (Nous avons créé nous-même un tel programme pour ajouter des métadonnées particulières aux deux photos ayant servi dans l'exercice précédent sur la chasse au trésor).
-
-
Que pouvez-vous penser quant à la date réelle de la première vidéo : le 16 janvier 2022 ou le 18 janvier 2022 ?
Quel aurait été l'intérêt de modifier par programme les métadonnées de cette vidéo ? -
Quelle conclusion géopolitique peut-on tirer de la datation de cette vidéo ?
-
-
-
Que pouvez-vous penser quant à la date réelle de la première vidéo : le 21 février 2022 ou le 24 février 2022 ?
Quel aurait été l'intérêt de modifier par programme les métadonnées de cette vidéo ? -
Quelle conclusion géopolitique peut-on tirer de la datation de cette vidéo ?
-
Vous pouvez vous aider de cet article.
Partie 2 : Formats des images
Introduction
Pour un ordinateur, une image est un ensemble de pixels arrangés sous la forme d'un tableau à deux dimensions.
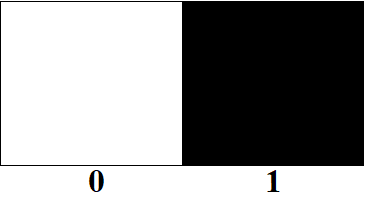
Une image dite en noir et blanc est composée de pixels noirs ou blancs ; les deux valeurs possibles des pixels sont 1 pour le noir et 0 pour le blanc.
Une image en niveaux de gris est composée de pixels de valeurs numériques représentant l'intensité de la luminosité, généralement les valeurs sont entières entre 0 (pour le noir) et 255 (pour le blanc).

Une image en couleurs est composée de pixels représentés par trois valeurs :
- j
celle représentant l'intensité du rouge (R),
-
celle représentant l'intensité du vert (V),
-
et celle représentant l'intensité du bleu (B).
Chaque valeur est comprise entre 0 et 255.
Voici une animation permmettant de visualiser que l'addition des trois couleurs rouge, verte et bleue permet de reconstituer
la couleur blanche, couleur qui correspond à la synthèse de toutes les couleurs visibles :
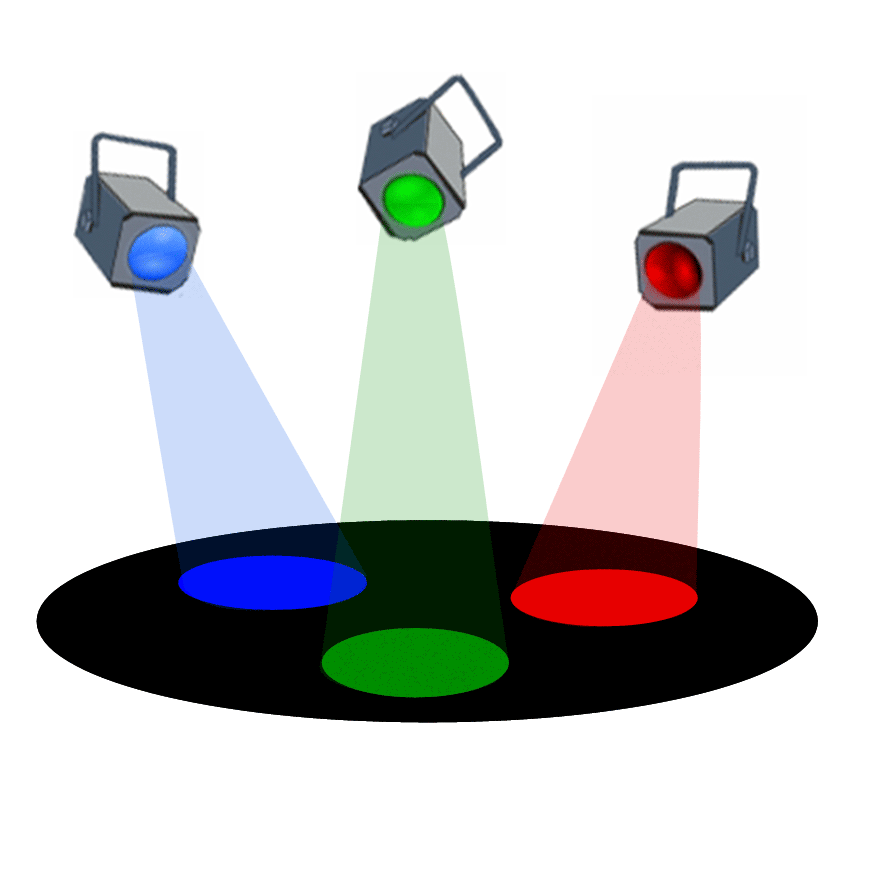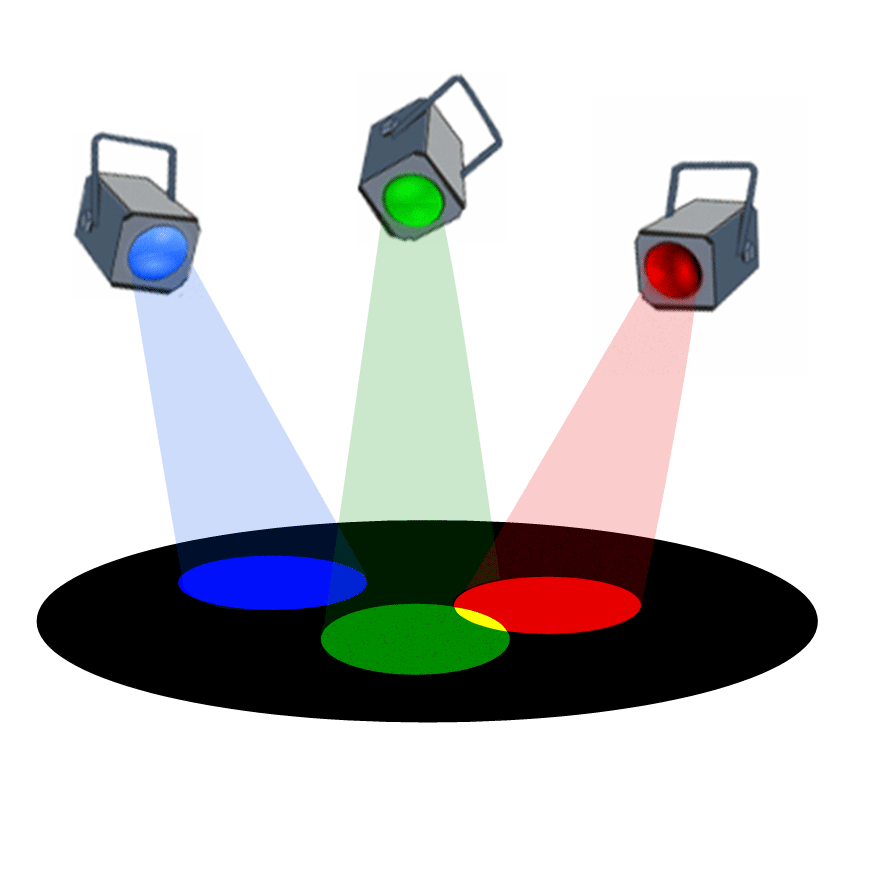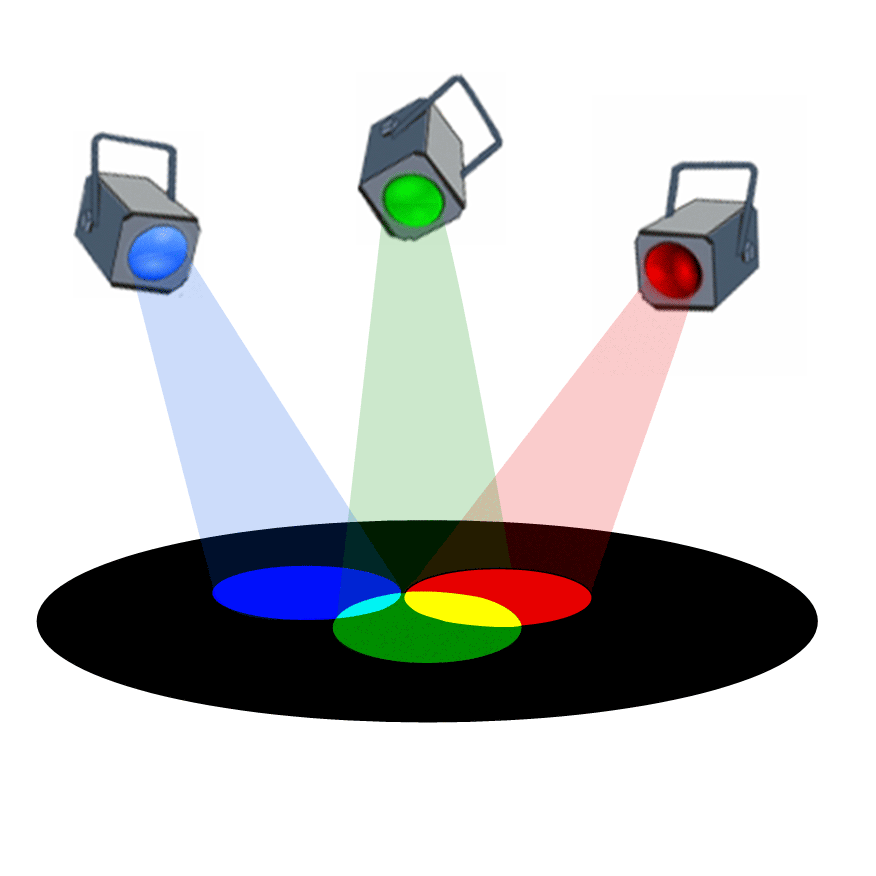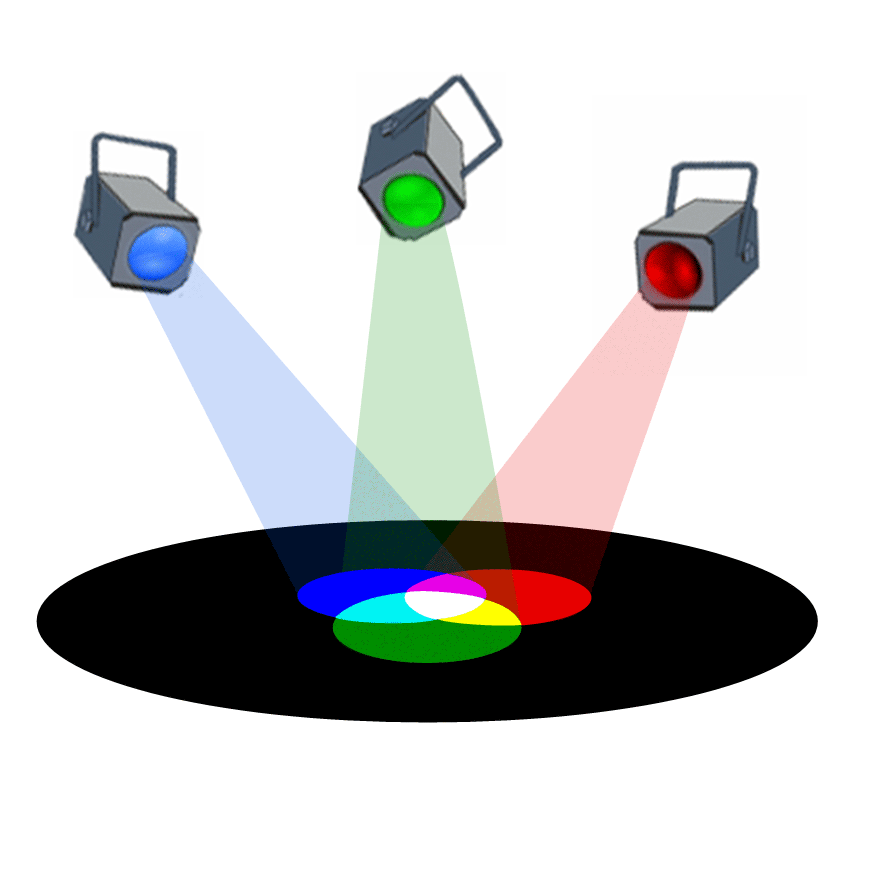
-
Pour chaque intensité de couleur, on parle ici d’un codage sur huit bits : en effet, chaque nombre compris entre 0 et 255 peut être associé à un « mot » de 8 bits (un tel mot est par exemple : 10010100 qui code la nuance 148).
-
Dans la suite, on parlera d'octet, 1 octet = 8 bits.
-
Cliquer sur le rectangle coloré ci-dessous pour faire apparaître toute une pallette de couleurs possibles :
-
Modifier les valeurs associées aux intensités de Rouge, Vert et Bleu afin afin de faire apparaître la couleur correspondant au code RVB : 135 ; 56 ; 204. Quelle couleur obtient-on approximativement ?
Voici une animation de
Chacun des projecteurs de couleur rouge, vert et bleu peuvent avoir désormais une intensité différente.
Jouer sur les curseurs colorés pour modifier les intensites respectives des projecteurs afin de répondre aux questions suivantes :
-
Quelle couleur approche-t-on lorsque le lrègle l'intensité rouge à peu près au $\dfrac{3}{4}$, celle verte à la moitié et celle bleue au quart ?
-
Quelle couleur obtient-on lorsque les trois intensités sont égales au tiers ?
-
Modifier les trois intensités de sorte quelles restent égales. Que pouvez-vous dire de la couleur obtenue ?
Les formats sans compression
Formats portables
Les formats de fichiers d’images PBM (portable bitmap), PGM (portable grayscalemap) et PPM (portable pixmap), offrent une solution simple à tout programmeur confronté au problème de la manipulation de fichiers d’images.
Ces formats n’effectuent pas de compression, c’est-à-dire que tous les pixels sont présents dans l’image. L’avantage de ces formats est la qualité des images car sans compression il n’y a pas de perte de qualité. En revanche cela donne des fichiers très volumineux car les pixels sont représentés par des caractères ASCII qui occupent 1 octet chacun.
Ces fichiers, avec les trois formats, sont construits sur la même base :
-
Le nombre « magique » du format (P1 pour les images en noir et blanc, P2 pour celles en niveaux de gris et P3 pour les images en couleurs).
-
Un caractère d’espacement qui peut être un espace, une tabulation ou un retour à la ligne.
-
La largeur de l’image (valeur décimale, codée en ASCII) suivie d’un caractère d’espacement, la longueur de l’image (valeur décimale, ASCII) suivie d’un caractère d’espacement.
-
Uniquement pour PGM et PPM : l’intensité maximum (valeur décimale comprise entre 0 et 255, codée en ASCII) suivie d’un caractère d’espacement.
-
Un caractère d’espacement qui peut être un espace, une tabulation ou une nouvelle ligne.
- Les valeurs des pixels de l’image :
-
sont données ligne par ligne en partant du haut.
-
Chaque ligne est codée de gauche à droite et contient moins de 70 caractères. De plus, toutes les lignes commençant par # sont ignorées.
Une vidéo pour vous aider à démarrer ce type d'exercice :
Voici un exemple de fichier en format PBM
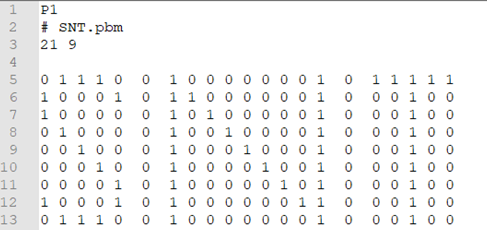
-
En utilisant un logiciel d'éditeur de textes (Visual Studio Code ou Notepad++ ou Bloc-notes), ouvrir le fichier "SNT.pbm" .
-
Quelle est la définition de ce fichier image ?
-
Calculer le poids de ce fichier sachant qu'un espace est un caractère, un retour à la ligne est représenté par deux caractères "/n" et chaque caractère quelle que soit sa nature occupe un octet.
-
En utilisant l'explorateur Windows, vérifier si votre calcul du poids de ce fichier est exact.
-
À partir de ce fichier deviner ce que cette image représente.
-
Ouvrir ce fichier à l'aide du logiciel GIMP. Zoomer pour visualiser convenablement cette nouvelle image (Avec GIMP, on utilise la touche plus "+" pour agrandir et moins "-" pour réduire).
-
Vérifier les caractéristiques dimensionnelles de cette image.
-
Ouvrir le bloc-notes de Windows, et saisir les deux premières lignes suivantes :

-
Compléter alors ce fichier, puis l’enregistrer au format PBM, de sorte qu’en l’ouvrant avec GIMP, on obtienne les images suivantes :
Image 1 Image 2 

Voici un exemple de fichier en format PGM
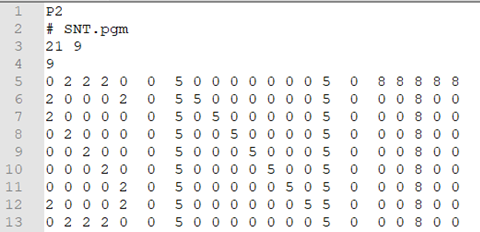
-
Quelle est la définition de ce fichier image ?
-
Que représente la valeur de la 4 ligne ? Deviner ce que cette image représente.
-
Calculer le poids de ce fichier.
-
En utilisant l'explorateur Windows, vérifier si votre calcul du poids de ce fichier est exact.
-
Ouvrir ce fichier à l'aide du logiciel GIMP. Zoomer pour visualiser convenablement cette nouvelle image (Avec GIMP, on utilise la touche plus "+" pour agrandir et moins "-" pour réduire).
-
Vérifier les caractéristiques dimensionnelles de cette image.
-
On présente ci-dessous des images de dimensions 4×4 pixels :
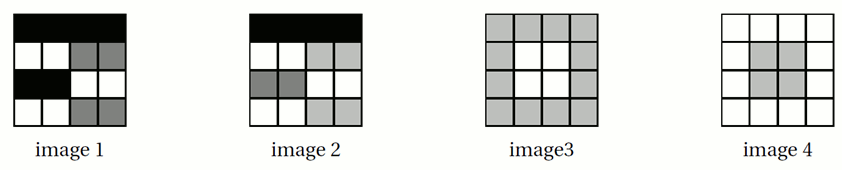
On considère les tableaux de nombres suivants :
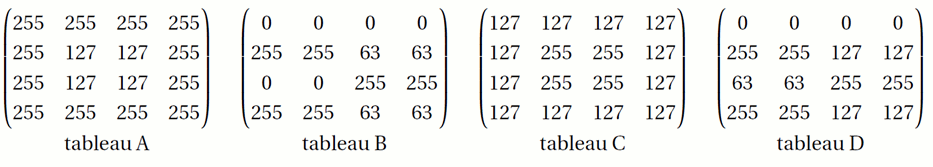
Associer à chaque image le tableau qui lui correspond.
En utilisant un logiciel d'éditeur de textes (Visual Studio Code ou Notepad++ ou Bloc-notes), ouvrir le fichier "SNT.pgm".
Voici un exemple de fichier en format PPM
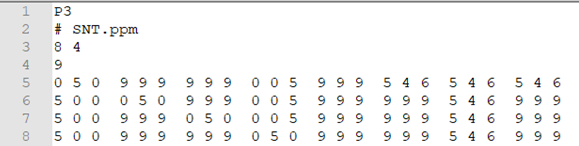
-
En utilisant un logiciel d'éditeur de textes (Visuel Studio Code ou Notepad++ ou Bloc-notes), ouvrir le fichier nommé "SNT.ppm" .
-
Quelle est la définition de ce fichier image ?
-
Que représente la valeur de la 4 ligne 3 ?
-
Calculer le poids de ce fichier.
-
En utilisant l'explorateur Windows, vérifier si votre calcul du poids de ce fichier est exact.
-
A partir de ce fichier deviner ce que cette image représente.
-
Ouvrir ce fichier à l'aide du logiciel GIMP. Zoomer pour visualiser convenablement cette nouvelle image (Avec GIMP, on utilise la touche plus "+" pour agrandir et moins "-" pour réduire).
-
Vérifier les caractéristiques dimensionnelles de cette image.
-
Combien de nuances de chaque composante peut-on obtenir ?
-
Combien de couleurs différentes peut-on obtenir ?
-
Reproduire et compléter le tableau ci-dessous :
| Couleur du pixel | Rouge | Vert | Bleu | Blanc | Noir | Jaune | Cyan | Magenta | Violet |
|---|---|---|---|---|---|---|---|---|---|
| Composante rouge | |||||||||
| Composante vert | |||||||||
| Composante bleu |
On trouve sur ce site un nuancier de couleurs RVB qui pourra être utile.
D'autres formats
Lors de la capture par l'appareil photo, un fichier au format Raw est produit. Il s'agit des données brutes issues du capteur. Ce format est donc brut et non compressé. En général, il est immédiatement modifié et enregistré dans un autre format. Il existe un autre non compressé, le format Tiff qui est adapté à l'impression.
Rechercher les caractéristiques de ces deux formats de fichiers images sans compression en complétant le tableau suivant :
| Format | Qualité | Poids |
|---|---|---|
| Raw | ||
| Tiff |
Les formats d’image représentant l’ensemble des pixels sont très volumineux. Il existe plusieurs mécanismes de compression de données qui réduisent la taille des fichiers.
Formats avec compression
Il y a deux grandes familles : les méthodes de compression d’image sans perte et celles avec perte.
Formats sans perte
L'une des méthodes les plus importantes de compression d’image sans perte est la méthode du codage des répétitions (comme LRE "run-length encoding")
Cet encodage consiste, pour chaque suite de pixels de la même couleur, à coder uniquement le nombre
de pixels puis la couleur de la séquence. Ainsi sur l’image noir et blanc représentée par la suite de pixels
blancs
(W) ou noirs (B) suivante :
WWWWWWWBWWWWWWWWWWWBBBBWWWWWWWWWWWWWWWWWWWWBWWWWWWWWW le codage est :
7W1B11W4B20W1B9W
En général le codage comporte moins de caractères (il y a bien compression). Mais ce n’est pas toujours le cas comme le montre l’image :
WBWBWBWBWB qui se code par 1W1B1W1B1W1B11W1B1W1B
Formats avec perte
Il existe de nombreuses techniques de compression avec perte. Certains algorithmes de compression utilisent le fait que l’oeil humain est assez sensible à la luminance (la luminosité) mais peu à la chrominance (la teinte) d’une image. Ainsi les pixels ayant des teintes proches sont uniformisés. Les couleurs sont donc modifiées afin d’être uniformes dans les zones ayant des teintes proches (ce que l’oeil humain a du mal à distinguer). Le processus de compression est irréversible, puisqu’il y a perte de données.
Rechercher les caractéristiques des principaux formats de fichiers images avec compression.
Préciser pour chaque format s'il peut être compresser avec ou sans perte des données, présenter ces résultats sous la forme d'un tableau.
| Format | Qualité | Poids | Compression | Transparence | Utilisable en web |
|---|---|---|---|---|---|
| ... | ... | ... | ... | ... | ... |
| ... | ... | ... | ... | ... | ... |
Partie 3 : Traitement d'images
Structures de base
Dans les travaux sur les images, on utilisera la bibliothèque PIL du langage de programmation Python.
Pour créer une nouvelle image qu'on utilise comme un fond de couleur noire, on doit importer d'abord
le module Image de la bibliothèque PIL et utiliser la fonction Image.new("RGB", (L , H), (R, V, B)).
- Le premier paramètre de cette fonction permet de préciser qu'il s'agit d'une image de codage RVB.
- Le second permet de créer une image d’affichage aux dimensions souhaitées :(500,400) crée une image de largeur 500 pixels et de hauteur 400 pixels.
- Le dernier (R, V, B) correspond au code couleur
Pour afficher une image, on utilise la fonction show()
from PIL import Image
couleur=(255,255,0) # couleur jaune en code couleur RVB : ici R=255, V=255 et B=0
fond=Image.new('RGB',(600,400),couleur) # création d'une image de de largeur 600 pixels et de hauteur 400 pixels, jaune
fond.show()
-
Dans le dossier "Photographie" créer un dossier et appeler le "partie3", ensuite créer, sous EduPython, un fichier nommé fond.py et l’enregistrer dans ce dossier
-
Dans ce fichier, recopier le script donné ci-dessus et l’exécuter. Vérifier les commentaires du code.
-
Modifier ce programme de sorte que le fond affiché soit de couleur vert pistache.
On trouve sur le site un nuancier de couleurs RVB qui pourra être utile.
-
Modifier ce programme de sorte que l'image soit désormais de 850 pixels de largeur et 560 en hauteurs et de couleur au choix.
On trouve sur ce site les plus de 16 millions possibles en code couleur RVB, faites-vous plaisir.
Extraction du code couleur sur une image
La pipette d'un logiciel de retouche de photo permet de récupérer le code RVB d'un pixel.
Ci-dessous, on a prélevé la couleur d'un même pixel sur une image en couleur, puis sur cette image après passage en niveaux gris.
 |

|
| Source des images : SNT 2de, Sciences numériques et Technologie, page 109, édition Delagrave, Paris 2019. | |
Pour chaque pixel, on calcule d’abord la valeur nommée $g$ en niveau de gris en fonction des trois valeurs de ses composantes $(r , v , b)$ en utilisant la formule suivante :
\[ g=0,11\times r+0,83\times v+0,06\times b\]-
Donner les trois composantes $(r , v , b)$ du pixel indiqué dans l'image en couleur ci-dessus.
-
Que représentent les trois valeurs $7 %$, $62 %$ et $79 %$ ? Comment obtient-on ces valeurs ?
-
Que représente la valeur $146$ indiquée sur l'image en niveau de gris ? Comment obtient-on cette valeur ?
-
Que représente la valeur $57 %$ ? Comment obtient-on cette valeur ?
Transformation d'une image RVB en niveaux de gris
Lecture et écriture d’un pixel en langage Python
Chaque pixel d’une image est repéré par ses coordonnées (x, y) et ses composantes (R,V,B).
Attention !
Les coordonnées des pixels d'une image sont liées à un repère particulier :
-
l'origine se trouve en haut, à gauche,
-
l'axe des abscisses est orienté de gauche à droite (de 0 à largeur),
-
l'axe des ordonnées de haut en bas (de 0 à hauteur).
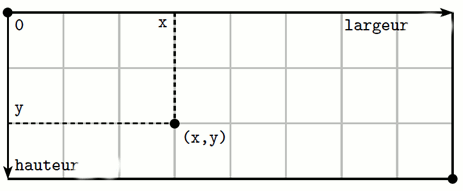
- Pour lire les informations (r, v, b) du pixel de coordonnées (x, y) de l’image nommée "im", on utilise l’instruction :
r,v,b =im.getpixel (( x , y ))Dans ces instructions, les coordonnées (x, y) sont données par rapport au coin supérieur gauche de l’image "im" (et pas par rapport au coin de la fenêtre).
largeur,hauteur=im.sizeNim=Image.new("RGB" , ( L, H )) # Création d'une nouvelle image nommée "Nim" de dimensions L et HNim.putpixel((x,y),(r,v,b))Niveau de gris
Dans ce paragraphe, nous allons décrire comment transformer une image en couleurs en une image en niveaux de gris.

Pour cela, il est nécessaire d’agir sur tous les pixels, les uns après les autres : à l’aide de deux boucles for imbriquées, on devra donc parcourir l’image entière par lignes et par colonnes.
for y in range (hauteur) :
for x in range (largeur) :Pour chaque pixel, on calcule d’abord la valeur en niveau de gris en fonction de ses trois composantes par la formule suivante :
\[ g=0,11\times r+0,83\times v+0,06\times b\]On remplace ensuite, pour ce pixel, la couleur (r, v, b) par la couleur (g, g, g).
Voici un algorithme permettant de transformer une image en couleurs en une image en niveaux de gris :
Algorithme :
Im ← ? # On charge une image en lui donnant le nom "Im" par exemple
L, H ← Im.size # On récupère les dimensions de l'image chargée
NegIm ← ? # On crée une nouvelle image nommée "GrisIm" de dimensions LxH
Pour y allant de 0 à H-1 : # On parcourt les pixels de l'image "Im" en hauteur
Pour x allant de 0 à L-1 : # On parcourt les pixels de l'image "Im" en largeur
r, v, b ← ? On récupère les composantes RVB du pixel de coordonnées (x ; y) de l'image "Im"
on affecte à g la partie entière de (0.11*r+0.83*v+0.06*b)
On affecte au pixel de l'image "GrisIm" de coordonnées (x ; y) les composantes (g, g, g)
Fin Pour
Fin Pour
On sauvegarde la nouvelle image "GrisIm" dans le dossier qu'on veut en lui donnant un nom
On affiche la nouvelle image "GrisIm"
Le but est que vous mettiez en oeuvre l'algorithme précédent sur l'image suivante :

pour aboutir à celle-ci :

Pour cela, on vous propose plusieurs exercices de niveau différent selon vos connaissances dans le langage Python :
-
le niveau fondamental si vous ne connaisez pas ou très peu Python, ne vous inquiétez pas ! Vous serez guidé.e.s pas à pas ;
-
le niveau confirmé si vous connaisez un peu Python et êtes capable d'extraire de l'information dispersée ;
-
le niveau expert si vous avez déjà une bonne expérience en Python et savez en particulier :
-
ouvrir et fermer une image particulière connaissant son adresse et son nom,
-
utiliser la documentation d'une bibliothèque,
Ce niveau dépasse largement le niveau attendu en fin de seconde et en SNT.
-
Cliquez sur le niveau d'exercice qui vous convient pour y accéder directement.
Vous pouvez traiter cet exercice directement sur le site capytale en saisissant le code d0c7-425916.
-
Dans le dossier "Photographie", créer un dossier et l'appeler "partie3"
-
Ouvrir l'image du perroquet en cliquant ici puis faire un clic droit et l'enregistrer dans le dossier "partie3".
-
Utilisation du langage Python :
-
Télécharger le fichier acccessible ici où une partie du programme en langage Python est déjà écrite et l'enregistrer dans le même dossier "partie3".
Attention à bien enregistrer ce fichier dans le même répertoire que l'image du perroquet sinon le programme ne sera pas fonctionnel car la quatrième ligne du code devrait être modifiée.
-
Compléter la ligne 6 du programme en utilisant l'instruction size présentée ici afin de stocker dans les variables
largeuretlongueurles deux dimensions de l'image initiale du perroquet. -
Compléter la ligne 8 du programme en utilisant l'instruction new présentée ici afin de stocker dans la variable nommée
imageButune image nouvelle créée dont les dimensions sont celles de l'image initiale.Penser à utiliser des variables déjà créées dans ce programme.
-
Compléter la ligne 13 du programme en utilisant l'instruction getpixel présentée ici afin de stocker dans les variables nommées
r,vetbles composantes RVB du pixel de coordonnées (x,y) de l'image du perroquet initiale.Penser à utiliser la variable déjà créée dans ce programme qui stocke l'image initiale du perroquet.
-
Compléter la ligne 15 du programme en utilisant la formule donnant le niveau de gris donnée ici afin de stocker dans la variable nommée
gle niveau de gris calculé.l'instruction
intpermet de ne garder que la partie entière (c'est-à-dire celle devant la virgule) du résultat du calcul. -
Compléter la ligne 17 du programme en utilisant l'instruction putpixel présentée ici afin de mettre le pixel de coordonnées (x,y) de l'image nouvellement construite au niveau de gris calculé.
Penser à utiliser une variable déjà créée dans ce programme.
Pour chacune des questions suivantes, lire le commentaire précédent la ligne du code à modifier et cliquer sur le lien afin d'obtenir un exemple d'utilisation qu'il suffit d'adapter.
-
-
Vérifier que l'image obtenue est similaire celle attendue.
-
Dans le dossier "Photographie", créer un dossier et l'appeler "partie3"
-
Ouvrir l'image du perroquet en cliquant ici puis faire un clic droit et l'enregistrer dans le dossier "partie3".
-
Utilisation du langage Python :
-
Télécharger le fichier accessible ici où une partie du programme en langage Python est déjà écrite et l'enregistrer dans le même dossier "partie3".
Attention à bien enregistrer ce fichier dans le même répertoire que l'image du perroquet sinon le programme ne sera pas fonctionnel car la quatrième ligne du code devrait être modifiée.
-
Compléter la ligne 6 du programme en utilisant l'instruction
sizeafin de stocker dans les variables imposéeslargeuretlongueurles deux dimensions de l'image initiale du perroquet. -
Compléter la ligne 8 du programme en utilisant l'instruction
newafin de stocker dans la variable nomméeimageButune image nouvelle créée dont les dimensions sont celles de l'image initiale. -
Compléter la ligne 13 du programme en utilisant l'instruction
getpixelafin de stocker dans les variables nomméesr,vetbles composantes RVB du pixel de coordonnées (x,y) de l'image du perroquet initiale. -
Compléter la ligne 15 du programme en utilisant la formule donnant le niveau de gris afin de stocker dans la variable nommée
gle niveau de gris calculé.l'instruction
intpermet de ne garder que la partie entière (c'est-à-dire celle devant la virgule) du résultat d'un calcul.int(1.2+3.4)renvoie 4 qui est la partie entière de 4.6, résultat de l'addition 1.2+3.4.
-
Compléter la ligne 17 du programme en utilisant l'instruction
putpixelafin de mettre le pixel de coordonnées (x,y) de l'image nouvellement construite au niveau de gris calculé.Penser à utiliser la variable déjà créée dans ce programme stockant la nouvelle image.
Pour chacune des questions suivantes, lire le commentaire précédent la ligne du code à modifier et cliquer sur le lien afin d'obtenir un exemple d'utilisation qu'il suffit d'adapter.
Penser à utiliser les différentes instructions présentées avec un exemple ici.
-
-
Vérifier que l'image obtenue est similaire celle attendue.
-
Dans le dossier "Photographie", créer un dossier et l'appeler "partie3"
-
Traduire l'algorithme de niveau de gris en langage Python pour pouvoir charger une image en couleur et l'afficher en niveaux gris.
Pour maîtriser les fonctions du module
Imagede la bibliothèquePIL, vous pouvez utiliser la documentation accessible ici -
Vérifier que l'image obtenue est similaire celle attendue.
Si vous êtes perdu, voici une aide en vidéo :
Le négatif d'une image
Le négatif d'une image est une image dont les couleurs sont inversées par rapport à l'originale c'est-à-dire :
-
Quand l'image originale est en noir et blanc alors son image négative est obtenue en remplaçant le noir par le blanc et le blanc par noir.
-
quand l'image originale est en niveaux gris alors si g est la valeur d'un pixel de l'image d'origine alors la valeur du pixel négatif correspondant est $255 - g$.
-
quand l'image originale est en RVB alors si $(r , v , b)$ sont les trois composantes d'un pixel de l'image d'origine alors les composantes du pixel négatif correspondant sont $(255 - r , 255 - v , 255 - b)$.
| 1. Parmi les images ci-dessous, laquelle est le négatif de l'image ci-contre ? |  |
| Image 1 | Image 2 | Image 3 | ||
 |

|
 |
| 2. Parmi les images ci-dessous, laquelle est le négatif de l'image ci-contre ? |  |
| Image 1 | Image 2 | Image 3 | ||
 |

|
 |
| 3. Parmi les images ci-dessous, laquelle est le négatif de l'image ci-contre ? |  |
| Image 1 | Image 2 | Image 3 | ||
 |

|
 |
Algorithme :
Voici un algorithme permettant de passer au négatif d'une image :
Im ← ? # On charge une image en lui donnant le nom "Im" par exemple
L, H ← Im.size # On récupère les dimensions de l'image chargée
NegIm ← ? # On crée une nouvelle image nommée "NegIm" de dimensions LxH
Pour y allant de 0 à H-1 : # On parcourt les pixels de l'image "Im" en hauteur
Pour x allant de 0 à L-1 : # On parcourt les pixels de l'image "Im" en largeur
r, v, b ← ? On récupère les composantes RVB du pixel de coordonnées (x ; y) de l'image "Im"
On affecte au pixel de l'image "NegIm" de coordonnées (x ; y) les composantes (255-r, 255-v, 255-b)
Fin Pour
Fin Pour
On sauvegarde la nouvelle image "NegIm" dans le dossier qu'on veut en lui donnant un nom
On affiche la nouvelle image "NegIm"
Le but est de vérifier les résultats de l'exercice précédent en appliquant l'algorithme ci-dessus aux trois images de l'exercice, images téléchargeables ci-dessous.
Ouvrir cette image en cliquant ici puis faire un clic droit et enregistrer la dans le dossier "partie3" sous le nom imposé loup.png (png étant le type de fichier, loup étant le nom du fichier)
Ouvrir cette image en cliquant ici puis faire un clic droit et enregistrer la dans le dossier "partie3" sous le nom imposé fleur.png.
Ouvrir cette image en cliquant ici puis faire un clic droit et enregistrer la dans le dossier "partie3" sous le nom imposé image.png.
Comme dans le précédent exercice de codage en langage Python, attention à enregistrer les images et le programme dans le même répertoire.
Là encore, on vous propose trois niveaux d'exercice pour mettre en oeuvre l'algorithme du négatif suivant votre maîtrise du langage Python :
-
le niveau fondamental si vous ne connaissez pas ou très peu Python, ne vous inquiétez pas ! Vous serez guidé.e.s pas à pas ;
-
le niveau confirmé si vous connaissez un peu Python et êtes capable d'extraire de l'information dispersée ;
-
le niveau expert si vous avez déjà une bonne expérience en Python et savez en particulier :
-
ouvrir et fermer une image particulière connaissant son adresse et son nom,
-
adapter un programme précédent,
-
Cliquez sur le niveau d'exercice qui vous convient pour y accéder directement.
-
-
Télécharger le fichier acccessible ici où une partie du programme en langage Python est déjà écrite et l'enregistrer dans le même dossier "partie3" .
Attention à bien enregistrer ce fichier dans le même répertoire que l'image du loup sinon le programme ne sera pas fonctionnel car la quatrième ligne du code devrait être modifiée.
-
Compléter la ligne 6 du programme en utilisant l'instruction size présentée ici afin de stocker dans les variables
largeuretlongueurles deux dimensions de l'image initiale du perroquet. -
Compléter la ligne 8 du programme en utilisant l'instruction new présentée ici afin de stocker dans la variable nommée
imageButune image nouvelle créée dont les dimensions sont celles de l'image initiale.Penser à utiliser des variables déjà créées dans ce programme.
-
Compléter la ligne 13 du programme en utilisant l'instruction getpixel présentée ici afin de stocker dans les variables nommées
r,vetbles composantes RVB du pixel de coordonnées (x,y) de l'image du loup initiale.Penser à utiliser la variable déjà créée dans ce programme qui stocke l'image initiale du loup.
Contrairement au programme mettant en niveau de gris l'image sur le perroquet,
getpixelrenvoie ici quatre valeurs car l'image du loup est une image multicouche d'où la création d'une nouvelle variableautre_infoqui ne nous servira pas ici. -
Compléter la ligne 15 du programme en utilisant :
-
l'instruction putpixel présentée ici afin de mettre le pixel de coordonnées (x,y) de l'image nouvellement construite à niveau de la couleur RVB correspondant au négatif.
Penser à utiliser des variables déjà créées dans ce programme.
-
Vérifier que l'image obtenue comme image négative du loup est bien celle déterminée comme résultat de l'exercice précédent.
-
Enregistrer le programme fini.
Dans un premier temps, on s'intéresse à compléter un script pour obtenir le négatif de l'image du loup.
Pour chacune des questions suivantes, lire le commentaire précédent la ligne du code à modifier et cliquer sur le lien afin d'obtenir un exemple d'utilisation qu'il suffit d'adapter.
De plus, s'aider du programme déjà réalisé sur le niveau de gris car les deux programmes sont proches. -
-
-
Enregistrer le programme prédécent sous un autre nom, nom dans lequel le mot "fleur" apparaît.
-
À la ligne 4 du programme, modifier le nom du fichier ouvert afin que le fichier "fleur.png" soit désormais ouvert par le programme.
-
Vérifier que l'image obtenue comme image négative de la fleur est bien celle déterminée comme résultat de l'exercice précédent.
-
Enregistrer de nouveau le programme fini.
Le but est désormais d'adapter le programme précédent pour obtenir l'image de la fleur.
-
-
-
Modifier le programme afin que ce soit le troisième image qui soit ouverte et que l'image créée ait un nom cohérent avec l'image initiale.
-
Vérifier que l'image obtenue comme image négative est bien celle déterminée comme résultat de l'exercice précédent.
-
-
-
Télécharger le fichier acccessible ici où une partie du programme en langage Python est déjà écrite et l'enregistrer dans le même dossier "partie3" .
Attention à bien enregistrer ce fichier dans le même répertoire que l'image du loup sinon le programme ne sera pas fonctionnel car la quatrième ligne du code devrait être modifiée.
-
Compléter la ligne 6 du programme en utilisant l'instruction
sizeafin de stocker dans les variables imposéeslargeuretlongueurles deux dimensions de l'image initiale du perroquet. -
Compléter la ligne 8 du programme en utilisant l'instruction
newafin de stocker dans la variable nomméeimageButune image nouvelle créée dont les dimensions sont celles de l'image initiale. -
Compléter la ligne 13 du programme en utilisant l'instruction
getpixelafin de stocker dans les variables nomméesr,vetbles composantes RVB du pixel de coordonnées (x,y) de l'image du perroquet initiale. -
Compléter la ligne 15 du programme en utilisant :
-
la formule donnant le négatif d'un pixel,
-
l'instruction putpixel afin de mettre le pixel de coordonnées (x,y) de l'image nouvellement construite à niveau de la couleur RVB correspondant au négatif.
-
-
Vérifier que l'image obtenue comme image négative du loup est bien celle déterminée comme résultat de l'exercice précédent.
Dans un premier temps, on s'intéresse à compléter un script pour obtenir le négatif de l'image du loup.
Pour chacune des questions suivantes, lire le commentaire précédent la ligne du code à modifier et cliquer sur le lien afin d'obtenir un exemple d'utilisation qu'il suffit d'adapter.
De plus, s'aider du programme déjà réalisé sur le niveau de gris car les deux programmes sont proches.Penser à utiliser les différentes instructions présentées avec un exemple ici.
Contrairement au programme mettant en niveau de gris l'image sur le perroquet,
getpixelrenvoie ici quatre valeurs car l'image du loup est une image multicouche d'où la création d'une nouvelle variableautre_infoqui ne nous servira pas ici. -
-
-
Modifier la ligne 4 du programme afin que le fichier nommé "fleur.png" soit désormais ouvert par le programme.
-
Vérifier que l'image obtenue comme image négative de la fleur est bien celle déterminée comme résultat de l'exercice précédent.
Le but est désormais d'adapter le programme précédent pour obtenir l'image de la fleur.
-
-
-
Modifier le programme afin que ce soit le troisième image qui soit ouverte et que l'image créée ait un nom cohérent avec l'image initiale.
-
Vérifier que l'image obtenue comme image négative est bien celle déterminée comme résultat de l'exercice précédent.
-
Il est possible de s'aider du programme déjà réalisé sur le niveau de gris car les deux programmes sont proches.
-
Écrire un script en Python permettant de traduire cet algorithme sur le négatif en sachant qu'il doit doit s'appliquer sur l'image du loup.
-
Modifier le programme afin d'obtenir le négatif de l'image du fleur.
-
Modifier le programme afin d'obtenir le négatif de la dernière image.
Contrairement au programme mettant en niveau de gris l'image sur le perroquet,
getpixel
renverra ici quatre valeurs car l'image du loup est une image multicouche.
La contraste
Le contraste d'une image est la variation relative de l'éclairement d'une image. Il permet de quantifier la différence de luminosité entre les parties claires et sombres d'une image.
quand l'image originale est en RVB, si $(r , v , b)$ sont les trois composantes d'un pixel de l'image d'origine alors pour jouer sur le contraste de cette image, on modifie les composantes du pixel en utilisant la formule suivante : $\text{nouvelleValeur} =128+ (\text{ancienneValeur} -128)*coef$.
- Où $coef$ est un réel :
- Si $0 <coef < 1$ alors l'image devient plus sombre
- Si $coef > 1$ alors l'image devient plus claire.
Algorithme :
Voici un algorithme permettant de modifier le contraste d'une image :
Im ← ? # On charge une image en lui donnant le nom "Im" par exemple
L, H ← Im.size # On récupère les dimensions de l'image chargée
Nim ← ? # On crée une nouvelle image nommée "Nim" de dimensions LxH
coef ← ? # On saisit le coeffcient du contraste
Pour y allant de 0 à H-1 : # On parcourt les pixels de l'image "Im" en hauteur
Pour x allant de 0 à L-1 : # On parcourt les pixels de l'image "Im" en largeur
r, v, b ← ? On récupère les composantes RVB du pixel de coordonnées (x ; y) de l'image "Im"
r1 ← partie entière de ((128+ (r -128)*coef)
v1 ← partie entière de ((128+ (v -128)*coef)
b1 ← partie entière de ((128+ (b -128)*coef)
On affecte au pixel de l'image "Nim" de coordonnées (x ; y) les composantes (r1, v1, b1)
Fin Pour
Fin Pour
On sauvegarde la nouvelle image "Nim" dans le dossier qu'on veut en lui donnant un nom
On affiche la nouvelle image "Nim"
Vous allez mettre en oeuvre cet algorithme sur l'image neige.jpg ci-dessous :

Suivant votre aisance dans le langage Python, chercher un des exercices suivant :
Si vous avez compris les deux exercices sur les nuances de gris et sur le négatif, n'hésitez pas à tenter la version confirmée au moins.
-
Télécharger le fichier acccessible ici où une partie du programme en langage Python est déjà écrite et l'enregistrer dans le même dossier "partie3" .
-
Compléter la ligne 4 du programme en précisant le nom du fichier où le contraste est à traiter.
-
Compléter la ligne 6 du programme en utilisant l'instruction size présentée ici.
-
Compléter la ligne 8 du programme en utilisant l'instruction new présentée ici.
-
Compléter la ligne 10 du programme, comme demandé dans l'algorithme de contraste, en affectant la valeur 1.5 à la varaible coeff.
-
Compléter la ligne 15 du programme en utilisant l'instruction getpixel présentée ici.
-
Compléter les lignes 17 à 19 du programme en utilisant la formule du contraste explicité dans l'algorithme de contraste.
l'instruction
intpermet de ne garder que la partie entière (c'est-à-dire celle devant la virgule) du résultat d'un calcul.int(1.2+3.4)renvoie 4 qui est la partie entière de 4.6, résultat de l'addition 1.2+3.4.
-
Compléter la ligne 20 du programme en utilisant :
l'instruction putpixel présentée ici. -
Compléter la ligne 22 du programme en donnant un nom à l'image créée où le contraste a été modifié.
Le format de l'image créée est identique à celle de l'image initiale.
-
Appliquer ce script à l'image neige.jpg téléchargée précédemment avec un coefficient
coefde 1.5. Que pouvez-vous dire de l'image obtenue ?
Pour chacune des questions suivantes, lire le commentaire précédent la ligne du code à
modifier et cliquer sur le lien afin d'obtenir un exemple d'utilisation qu'il suffit
d'adapter.
De plus, s'aider des programmes déjà réalisés sur le niveau de gris et sur le négatif
est utile car les trois programmes sont proches.
-
Dans Edupython, copier le script obtenu pour l'algorithme permettant d'obtenir le négatif d'une image.
-
Modifier le nom des fichiers images ouvert et obtenu.
-
Rajouter, comme demandé dans l'algorithme de contraste, une ligne où vous imposer la valeur de
coef, coefficient de contraste. -
Rajouter, comme demandé dans l'algorithme de contraste, les lignes permettant d'obtenir les nouvelles valeurs des couleurs RVB.
-
Appliquer ce script à l'image neige.jpg téléchargée précédemment avec un coefficient
coefde 1.5. Que pouvez-vous dire de l'image obtenue ?
-
Écrire un script en Python permettant de traduire l'algorithme de contraste. .
-
Appliquer ce script à l'image neige.jpg téléchargée précédemment avec un coefficient
coefde 1.5. Que pouvez-vous dire de l'image obtenue ?
Partie 4 : Algorithme de photomaton
Fond en couleur
Dans le script ci-dessous, l'image qui s’affiche est un carré de couleur noire.
from PIL import Image
fond=Image.new('RGB',(600,400))
fond.show()
Il est possible de modifier sa couleur, en utilisant le codage RVB vu précédemment :
Pour cela, on rajoute à la fonction Image.new() un troisième paramètre qui permet d'avoir un fond de couleur souhaitée ; par exemple, (255,255,255) crée un fond blanc.
from PIL import Image
couleur=(254,163,71)
fond=Image.new('RGB',(600,400),couleur)
fond.show()
Exécuter le script de l'exemple précédent.
Quelle couleur de fond est affichée ?
Quand une image créée, elle est caractérisée par ses dimensions (largeur et hauteur), et chaque pixel de cette image est repéré par ses coordonnées ($x$ et $y$).
L’origine se trouve en haut, à gauche. L’axe des abscisses est orienté de gauche à droite (de 0 à largeur), et l’axe des ordonnées de haut en bas (de 0 à hauteur) :
Une fois l'image est chargée, on peut récupérer ses dimensions comme suit :
im = Image.open("Images/maisons.png") # chargement de l'image maisons.png se trouvant dans le dossier Images
L,H=im.size # récupération des dimensions
Collage d'une image
Pour insérer une image dans un fond déjà créé, deux étapes sont nécessaires :
-
charger l’image et lui donner un nom :
-
coller l’image à l’endroit souhaité dans le fond déjà créé :
im = Image.open("images/souris.png")
La source de l’image est le fichier souris.png située dans le dossier nommé images. L’image chargée est appelée
im.
fond.paste(im, (x,y,x+L,y+H))
L’image nommée im est collée sur l'image créée appelée fond. Le coin supérieur gauche de l’image est positionné au point de coordonnées $(x,y)$ et le coin inférieur droite de l’image est positionné au point de coordonnées $(x+L,y+H)$, où $L$ et $H$ sont les dimensions de l'image chargée.
Voici un script permettant de coller une image sur un fond et l'afficher :
from PIL import Image
im = Image.open("Images/souris.png")
L,H=im.size
couleur=(190,245,116)
fond = Image.new('RGB',(600,500),couleur)
fond.paste(im, (100,100,100+L,100+H))
fond.show()
fond.save("Images/sourisModifiee.png", "PNG")
On obtient le résultat ci-dessous :

-
Dans le dossier "Photographie", créer un dossier et l'appeler "partie4".
-
Tester le code précédent.
Télécharger l'image la souris en cliquant ici puis faire un clic droit et enregistrer la dans un nouveau dossier qu'on nomme "partie4" dans le dossier "Photographie"
L'objectif désormais est de créer un programme python qui :
-
charge une image initiale,
-
créé une nouvelle image de largeur doublé,
-
place dans cette image deux images initiales identiques collées l'une à l'autre.
Si on prend par exemple l'image suivante :
On obtiendra à l'aide du script l'affichage suivante :

Suivant votre aisance dans le langage Python, chercher un des deux exercices suivant :
-
Télécharger le fichier Python suivant.
Enregistrer le dans le dossier "partie4". -
Télécharger l'image du perroquet ici.
Enregistrer la dans le même dossier "partie4". -
Compléter la ligne 6 afin que
largeurethauteurstockent respectivement la largeur et la hauteur de l'imageimageSource. -
Compléter la ligne 8 de sorte que
fenetresoit deux fois plus large queimageSourceet de même hauteur. -
Compléter la ligne 10 de sorte qu'une première copie d'
imageSourcesoit placée toute à gauche defenetre. -
Compléter la ligne 12 de sorte qu'une seconde copie d'
imageSourcesoit placée tout contre la première dansfenetre. -
Vérifier graphiquement que l'image créée correspond bien à celle attendue.
{kind=link}
-
Créer un nouveau fichier Python nommé double_image.py.
-
Ouvrir cette image en cliquant ici puis faire un clic droit et enregistrer la dans le dossier "partie4".
-
Rédiger un script permettant d’afficher deux images identiques l'une à côté de l'autre.
Algorithme de Photomaton
La transformation du photomaton peut être décrite de la façon suivante :
-
on part d’une image carrée (dont les dimensions sont des nombres pairs), et on la découpe en quatre carrés de mêmes dimensions ;
-
on envoie les quatre pixels situés dans le coin supérieur gauche de l’image initiale, aux coins supérieurs gauches des quatre carrés ;
-
on envoie les quatre pixels suivants de l’image initiale à la position suivante dans chacun des carrés, puis on répète cette opération pour tous les groupes de quatre pixels de l’image initiale.
Si on illustre cette situation avec une image de dimensions $8\times 8$, on obtient :
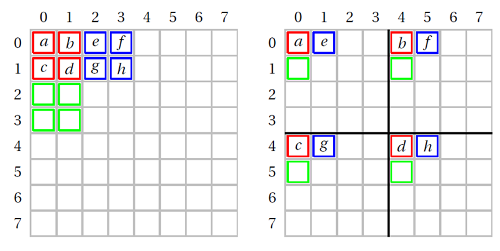
Le tableau suivant indique, pour quelques pixels, leurs coordonnées initiales et leurs coordonnées finales :
| pixel | a | b | c | d | e | f | g | h |
|---|---|---|---|---|---|---|---|---|
| coordonnées initiales | (0 ; 0) | (1 ; 0) | (0 ; 1) | (1 ; 1) | (2 ; 0) | (3 ; 0) | (2 ; 1) | (3 ; 1) |
| coordonnées finales | (0 ; 0) | (4 ; 0) | (0 ; 4) | (4 ; 4) | (1 ; 0) | (5 ; 0) | (1 ; 4) | (5 ; 4) |
En appliquant la transformation du photomaton à une photographie, on obtient par exemple les images suivantes (les quatre petites images sont semblables à la grande image de gauche, mais elles ne sont pas identiques) :
 |
 |
On constate que :
-
La petite image dans le carré situé en haut à gauche est constituée par les pixels d'abscisse paire et d'ordonnée paire de la grande image,
-
La petite image dans le carré situé en haut à droite est constituée par les pixels d'abscisse impaire et d'ordonnée paire de la grande image,
-
La petite image dans le carré situé en bas à gauche est constituée par les pixels d'abscisse paire et d'ordonnée impaire de la grande image,
-
La petite image dans le carré situé en bas à droite est constituée par les pixels d'abscisse impaire et d'ordonnée impaire de la grande image.
Algorithme
Cet algorithme nous permet de sauvegarder la petite image située dans le carré en haut à gauche
im ← ? # On charge une image en lui donnant le nom "Im" par exemple
L, H ← Im.size # On récupère les dimensions de l'image chargée qui sont deux entiers pairs.
l ← L/2
h ← H/2
Nim ← ? # On crée une nouvelle image nommée "Nim" de dimensions lxh
Pour y allant de 0 à H-1 : # On parcourt les pixels de l'image "Im" en hauteur
Pour x allant de 0 à L-1 : # On parcourt les pixels de l'image "Im" en largeur
si x est pair et y est pair alors
r, v, b ← ? On récupère les composantes RVB du pixel de coordonnées (x ; y) de l'image "Im"
x1 ← x//2 # on affecte à x1 le quotient de x par 2
y1 ← y//2 # on affecte à x1 le quotient de x par 2
On affecte au pixel de l'image "Nim" de coordonnées (x1 ; y1) les composantes (r, v, b)
Fin Pour
Fin Pour
On sauvegarde la nouvelle image "Nim" dans le dossier qu'on veut en lui donnant un nom
On affiche la nouvelle image "Nim"
-
Traduire cet algorithme en langage Python.
Pour obtenir la partie entière d'un nombre
npar sa division par 2 (=quotient de la division euclidienne par 2), il suffit de saisir en python :n//2 -
ouvrir cette image en cliquant ici puis faire un clic droit et enregistrer la dans le dossier "partie4" qu'on a déjà créé.
-
Appliquer ce script à "maisons.png" et sauvegarder la nouvelle image sous le nom "maisonsPhoton.png".
-
Déterminer la définition et le poids de chacune des deux images.
Écrire un script en langage Python permettant d'afficher les quatre petites images obtenues par la méthode de l'algorithme du photomaton.
Pour obtenir à la fin l'image suivante :
Pour aller loin :
Modifier ce script pour qu’il affiche l’image transformée pendant quelques secondes, puis la transforme à son tour, et recommence ...
Pour obtenir à la fin l'image suivante :

Retouche d'image
Le but est de découvrir comment retoucher simplement des images à l'aide du logiciel GIMP, logiciel que vous avez réinstallé en début de thème.
Vous allez retoucher les deux images accessibles ci-dessous :
Pour découvrir Gimp et certaines de ses fonctionnalités, il vous suffit de suivre pas-à-pas le document ci-dessous afin de modifier la photographie avec des yeux rouges :
Une petite aide en vidéo.
Pour apprendre à modifier les deux images précédentes, il vous suffit de suivre pas-à-pas le document ci-dessous :
Attention ! Une fois que vous avez terminé votre travail, vous devez l'envoyer à votre enseignant en suivant la procédure précisée en fin de document.
Savoir repérer des images modifiées
Objectif de la partie
Vous avez vu dans la partie précédente, qu'il est aisé de modifier des photographies à l'aide de logiciel.
En tant que citoyen.ne, il est important que vous appreniez à devenir capable de reconnaître si une photographie a été retouchée ou non.
Dans cette partie, vous aurez à repérer si les deux images ci-dessous, issues de réseaux sociaux ou de médias, sont des photos réelles ou des photos retouchées.
 |
 |
Cette partie est inspirée d'un travail proposé par le groupe de formateurs en SNT de l'académie de Reims.
Découverte d'un site
Le site suivant permet d'étudier si une photographie a été retrouchée ou non :
photo-forensics
Une image y apparaît ; est-elle vraie ou pas ?

Différents outils sont disponibles pour étudier si cette image est réelle ou non.
Si vous voulez découvrir chaque outil proposé, vous pouvez visionner une vidéo en anglais à ces adresses :
Premier outil : recherche d'éléments dupliqués
Aller sur le site photo-forensics.
Une image est parfois retouchée en dupliquant des parties (un peu comme vous aviez fait pour supprimer les boutons du visage).
|
L'outil Clone Detection du site permet de détecter en partie cela : Cliquer sur Clone Detection. |
 |
-
Régler les paramètres "Minimal Similarity", "Minimal detail" du bandeau de droite.
Attendre un peu de temps pour que le serveur, ayant pris en compte les paramètres choisis, calcule et vous envoie le résultat de l'analyse.
Suivant les valeurs prises, vous verrez apparaître une image proche de celle-ci :

-
Les traits roses relient différentes parties qui semblent être une copie l'une de l'autre.
Que pouvez-vous en déduire quand à la photo initiale ?
-
Importer sur le site l'image que vous avez retouchée pour la séance précédente sur GIMP.
-
Régler les paramètres pour visualiser si vos duplications sont repérées ou non.
Deuxième outil : recherche d'une granularité différente
Lorsqu'une image est modifiée, des pixels sont modifiés par des algorithmes et le "grain" de l'image est modifié.
|
L'outil Magnifier du site permet de détecter en partie cela : Cliquer sur Magnifier. |
 |
-
Régler les paramètres "Magnification" du bandeau de droite.
-
Déplacer la souris sur l'image : vous verrez une portion de celle-ci zoomée, ce qui vous permet d'observer pixel par pixel.
Par exemple, en plaçant la souris sur le pilote du parapente, on voit que les pixels sont différents tout autour.

-
Que pouvez-vous en déduire quand à la photo initiale ?
Troisième outil : recherche de zones manipulées
Des algorithmes permettent de reconnaître les zones probablement manipulées ou modifiées.
|
L'outil Error Level Analysis du site permet de détecter en partie cela : Cliquer sur Error Level Analysis. |
 |
-
Régler les paramètres "JPEG Quality", "Error Scale" et "Opacity" du bandeau de droite.
-
Avec certains niveaux choisis pour les réglages, vous pouvez obtenir :

Que pouvez-vous en déduire quand à la photo initiale ?
Quatrième outil : recherche des métadonnées
Des algorithmes permettent de reconnaître les zones probablement manipulées ou modifiées.
Dans tout fichier image, outre le codage des pixels, différentes données sont stockées mais non visibles directement : ce sont les métadonnées.
Certaines de cette métadonnées, si elles n'ont pas été effacées ou modifiées par un codage informatique, peuvent relever la géolocalisation de la photographie ou même l'image initiale avant retouche !
|
L'outil Meta Data du site permet de détecter en partie cela : Cliquer sur Meta Data. |
 |
-
Faire défiler la liste des métadonnées obtenues
-
Que pouvez-vous en déduire quand à la photo avec la soucoupe volante ?
-
Est-ce que les informations disponibles permettent d'affirmer ou d'infirmer les conclusions obtenues avec les outils précédents ?
Application sur les deux images
Vous pouvez télécharger les deux images ci-dessous par clic droit.
|
|
Les réponses à cet exercice seront écrites dans un document LibreOffice (ou Word) accompagnées de la copie d'écrans obtenus lors du travail sur le site.
-
Utiliser le site précédemment utilisé photo-forensics pour savoir si la première image, celle du tir des missiles, a été modifiée ou pas.
Vous devez faire des copies d'écran montrant comment vous avez utilisé le site et rédiger comment vous interprétez les résultats obtenus.
-
Utiliser le site précédemment utilisé photo-forensics pour savoir si la deuxième image, celle sur le pic-vert et la belette, a été modifiée ou pas.
Vous devez faire des copies d'écran montrant comment vous avez utilisé le site et rédiger comment vous interprétez les résultats obtenus.
-
Effectuer une recherche Internet (vous pouvez utiliser certains outils proposés dans la remarque ci-dessous) pour vérifier ce que vous avec devinez quant à ces deux photos.
Vous devez citer sur votre document les sites consultés ainsi que les informations que vous y avez trouvées.
Comme en tant que citoyen.ne, il est essentiel que vous ne vous fassiez pas avoir par de fausses images, nous vous proposons d'autres outils pour savoir si des photos ont été modifiées ou détournées ; en voici quelques-uns :
pour détecter l'origine d'une image, plusieurs sites existent :
-
le moteur de recherche russe Yandex
Voici une video expliquant comment utiliser un moteur de recherche pour trouver l'origine d'une photographie.
Sur les réseaux sociaux et plus généralement sur le Web, de nombreuses images sont publiées à des fin de propagande.
Actuellement, la guerre en Ukraine conduit à la publication de vidéos et d'images qui peuvent être fausses.
Voici deux exemples :
Un exemple de deepfake
La technologie actuelle (en particulier certaines branches de l'intelligence artificielle) permet de créer de fausses vidéos
à partir de vidéos réelles : cela s'appelle en franglais un deepfake.
Afin de démoraliser la résistance ukrainienne, le 16 mars 2022, un groupe de pirates informatiques a fait diffuser
par la chaîne de télévision Ukraine 24 une vidéo deepfake dans laquelle le président Zelensky appelait ses soldats et ses
compatriotes à déposer les armes.

Cette fausse information a été relayée ensuite sur différents réseaux sociaux. Elle était devenue virale sur Facebook avant que
cette plateforme ne décide de la supprimer.
Le président Zelensky a évidemment dénoncé cette manipulation.
-
Visionner cette vidéo :

Quelle méthode propose la vidéo pour repérer une vidéo deepfake ?
Un exemple d'image trafiquée
Avant l'invasion russe en Ukraine du 24 février 2022, un conflit avait lieu depuis 2014 dans le Donbass, province ukrainienne
dont une partie de la population pro-russe s'est proclamée indépendante.
Différents combats ont lieu depuis.
Le jeudi 17 février, à 8h45, un obus a éventré le mur d'une école maternelle d'une petite ville en périphérie de Louhansk,
ville du Donbass. Cette petite ville est contrôlée alors par l'Ukraine mais la ligne de démarcation avec les insurgés pro-russes
est toute proche. Le gouvernement ukrainien a accusé les séparatistes de Louhansk de ce bombardement.

Sur les réseaux sociaux s’est diffusée ensuite cette image semblant montrer que la destruction a été causée par un engin de chantier.
 (source : ce compte twitter )
(source : ce compte twitter )
L’auteur de l’image a publié 3 heures plus tard
une autre image, issue de Photoshop, un logiciel de retouche d'image, similaire à GIMP mais payant.
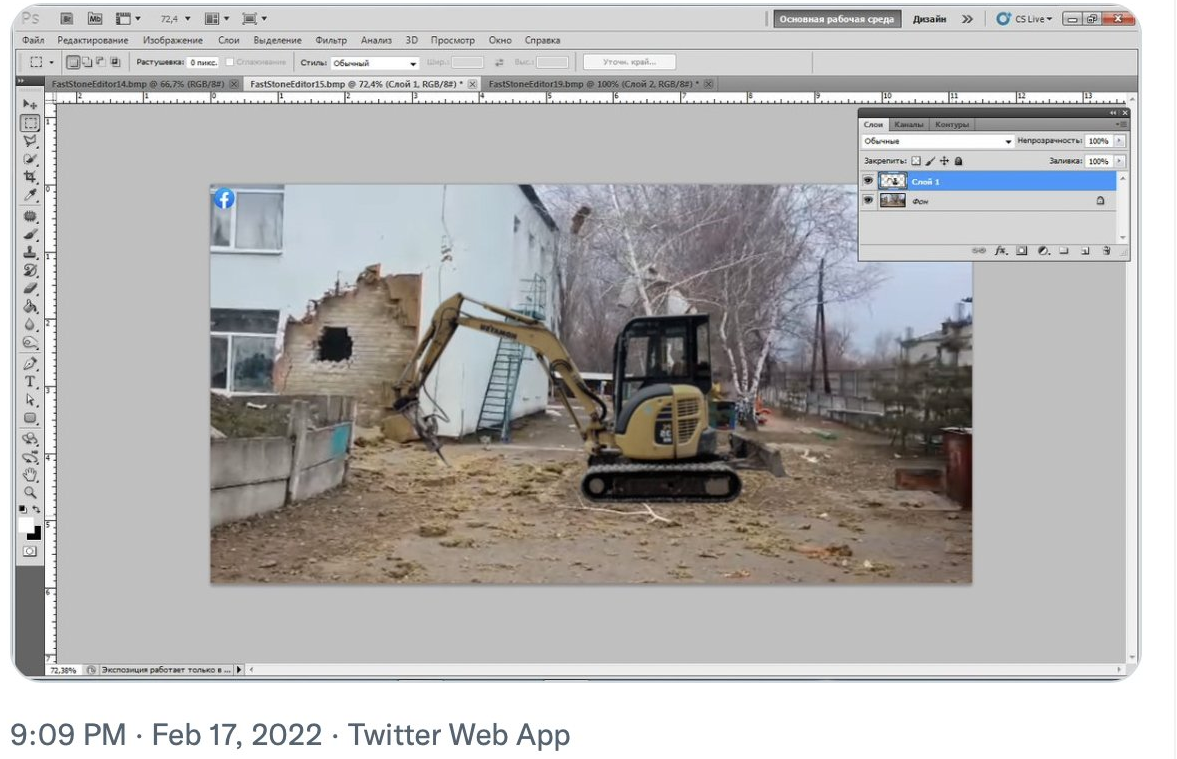 .
.
-
Quelles différences remarquez-vous entre les deux photos ?
-
Quelle "vérité" les changements opérés sur Photoshop veulent-ils montrer ?
-
À votre avis, pourquoi l’auteur de l’image a-t-il choisi de publier la photo originale et comment il y l'a retouché sur Photoshop ?
-
D’autres images ont été publiées le lendemain par Eliot Higgins, fondateur de Bellingcat, site de journalisme d'information à partir de données ouvertes. En voici une :
 (source : ce compte twitter)
(source : ce compte twitter)
Avec par exemple Tineye, vous pouvez vérifier l’origine de cette photo.
Vérifiez si cette photo a été truquée ou non.
Voici quelques images issues d'une étude de 2017 de Sophie Nightingale de l'Université de Warwick.
Repérer si ces images sont fausses ou non ; si elles sont fausses, déterminer porquoi.
|
Image 1 
|
Image 2 
|
|
Image 3 
|
Image 4 
|
|
Image 5 
|
Image 6 
|
|
Image 7 
|
Image 8 
|
Ces images sont issues d'une étude universitaire.
Cette étude a montré à partir d'un panel de 700 personnes que :
-
40% des personnes ne pouvaient différencier une photo truquée d'une photo réelle,
-
Parmi ceux qui pensait qu'une photo était truquée, seulement 45% pouviaent identifier le trucage,
-
L'étude pointe la menace contre nos démocraties que pose le développement de propagande à base de fausses images et plus généralement de fausses vidéos et de fausses informations : en tant que citoyen.ne.s, nous sommes peu capables de facilement repérer leur fausseté.
Vous pouvez accéder à la publication (en anglais) de l'article scientifique universitaire à cette adresse.
Voici quelques vidéos qui permettent d'apprendre à repérer si une image est modifiée ou détournée :
Une dernière vidéo qui permet d'apprendre à repérer si une vidéo a été modifiée .
QCM : Questionnaire pour vérifier ses acquis
Cliquez ici pour ouvrir le QCM afin de vérifier vos acquis
Cours de synthèse
Une synthèse de l'ensemble du cours.

Les différents
auteurs mettent l'ensemble du site à disposition selon les termes de la licence Creative
Commons Attribution - Pas d’Utilisation Commerciale - Partage dans les Mêmes Conditions 4.0
International