Le développement des traitements informatiques nécessite la manipulation de données de plus en plus nombreuses. Leur organisation et leur stockage constituent un enjeu essentiel de performance. Le recours aux bases de données relationnelles est aujourd’hui une solution très répandue. Ces bases de données permettent d’organiser, de stocker, de mettre à jour et d’interroger des données structurées volumineuses utilisées simultanément par différents programmes ou différents utilisateurs. Cela est impossible avec les représentations tabulaires étudiées en classe de première. Des systèmes de gestion de bases de données (SGBD) de très grande taille (de l’ordre du pétaoctet) sont au centre de nombreux dispositifs de collecte, de stockage et de production d’informations. L’accès aux données d’une base de données relationnelle s’effectue grâce à des requêtes d’interrogation et de mise à jour qui peuvent par exemple être rédigées dans le langage SQL (Structured Query Language). Les traitements peuvent conjuguer le recours au langage SQL et à un langage de programmation. Il convient de sensibiliser les élèves à un usage critique et responsable des données.
- Contenus : Base de données relationnelle.
- Capacités attendus: Savoir distinguer la structure d’une base de données de son contenu. Repérer des anomalies dans le schéma d’une base de données.
- Commentaires : La structure est un ensemble de schémas relationnels qui respecte les contraintes du modèle relationnel. Les anomalies peuvent être des redondances de données ou des anomalies d’insertion, de suppression, de mise à jour. On privilégie la manipulation de données nombreuses et réalistes.
- Contenus : Système de gestion de bases de données relationnelles.
- Capacités attendus: Identifier les services rendus par un système de gestion de bases de données relationnelles : persistance des données, gestion des accès concurrents, efficacité de traitement des requêtes, sécurisation des accès.
- Commentaires : Il s’agit de comprendre le rôle et les enjeux des différents services sans en détailler le fonctionnement.
Les chapitres qui peuvent être mis en relation avec ce chapitre sont :
Base de données relationnelles
Nous avons défini le modèle relationnel dans le chapitre précédent.
Pour utiliser concrètement ce modèle assez abstrait, on utilise un
système de gestion de bases de données.
Un système de gestion de base de données (SGBD) est un logiciel
servant d'interface entre l'utilisateur et les données.
Un SGBD permet de stocker, de trouver, de modifier, de trier,
de transformer des données contenues dans une base de données.
Tout SGBD utilise un langage de requêtes qui permet d'interroger et de
manipuler la base de données.
En NSI, nous utiliserons le langage SQL
(Structured Query Language : langage de requêtes structurées).
Il existe différents types de SGBD : hiérarchiques, relationnels, orientés objet, etc.
Dans le programme de terminale NSI, nous nous intéressons aux SGBD relationnels.
Le vocabulaire utilisé dans un SGBD diffère du vocabulaire utilisé dans le modèle relationnel.
Voici un tableau qui va vous permettre de vous y retrouver.
Attention toutefois, les notions ne sont pas équivalentes.
| Modèle relationnel | SGBD |
|---|---|
| relation | table |
| attributs | colonnes |
| $n$-uplet | lignes |
Il existe de nombreux SGBD. Certains SGBD sont payants, d'autres sont libres.
Les différences entre les SGBD se font également en fonction du nombre de données traitées
ainsi que son hébergement.
Certains SGBD sont des logiciels (voire une composante
d'un logiciel), d'autres aussi des serveurs.
Voici une liste non exhaustive :
- Apache Derby
- DB2
- dBase
- MariaDB
- Microsoft SQL server
- MySQL
- Oracle Database
- PostgreSQL
- SQLite
Vous pouvez faire une recherche sur l'historique des SGBD et sur ses enjeux.
Rôle et fonctions d'un SGBD
Un SGBD doit assurer un ensemble de fonctions :
-
Le SGBD doit assurer la persistance des données.
Il doit assurer la pérennité de la structure et la qualité des informations quelles que soient les modifications. De plus l'accès aux données doit être garanti en toute circonstance : panne matérielle, logicielle, coupure de courant, etc. -
Le SGBD doit gérer les accès concurrents.
Tout comme le système d'exploitation Linux étudié en première, il gère un système de droits et de privilèges pour des utilisateurs et des groupes d'utilisateurs. Il doit gérer ainsi la confidentialité des informations. -
Le SGBD doit être efficace.
Cette efficacité tient à des algorithmes puissants qui ne sont pas 'visibles' par les utilisateurs.
Langage SQL pour la définition des données
Nous avons vu que notre base de données est un ensemble de schémas que nous pouvons implanter par la création de tables.
Créer une base de données n'est pas explicitement au programme de Terminale NSI, nous allons simplement étudier les ordres qui permettent d'implémenter d'un point de vue logiciel une base de données.
- Lors de la création d'une
-
lui donner un nom,
-
indiquer ses attributs,
-
indiquer les différents types des attributs,
-
indiquer les contraintes d'intégrité (clés primaires, clés étrangères, contraintes de domaines, etc),
- ...
table, on peut :
Le langage SQL utilise des mots clés et une syntaxe à respecter. Par exemple la commande qui permet la création de la table series :
CREATE TABLE serie (
idSerie int(11) NOT NULL,
nomSerie varchar(30) NOT NULL,
desSerie TEXT,
AnneeSerie DATE,
nbSaison int(11)NOT NULL,
PRIMARY KEY (idSerie)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Vous remarquerez le ; à la fin de la commande. Les espaces et l'indentation n'ont pas d'incidence, cela facilite simplement la lecture.
En observant la syntaxe de la création de la table serie, indiquer les attributs, les domaines et les contraintes d'intégrité de cette table.
Python et SQL
Nous utiliserons une autre architecture pour travailler les bases de données, mais regardons du côté du logiciel Python.
Il existe une API (Application Programming Interface) en langage python qui s'appelle sqlite3
qui permet d'utiliser le langage SQL.
On considère le schéma relationnel : Artiste(idArtiste,nom,prénom,annéeNaiss) avec :
-
idArtiste comme clé primaire de la relation Artiste,
-
nom, prénom et annéeNaiss sont trois attributs de la relation Artiste.
En utilisant le trinket (ou en copiant le code dans l'IDLE Python de votre choix), observer et analyser le code ci-dessous :
-
En ajoutant des enregistrements dans la liste
data_artistspour ajouter des enregistrements dans la table Artiste. -
En modifiant la liste
data_artistspour avoir deux fois le même enregistrement. Essayer d'insérer vos nouvelles données.
Que se passe-t-il ? Expliquer pourquoi.
Modifier le code Trinket ci-dessus :
-
La ligne
bdd = sqlite3.connect(":memory:")permet de stocker les données de la base de données dans la RAM dans un objet appelé icibdd.Ceci a un défaut : les données sont perdues lors de la déconnexion (avec
bdd.close()) et lors de l'arrêt de l'ordinateur.Par contre, ceci a deux avantages :
-
L'accès à la RAM est plus rapide que celui à un disque dur,
-
En cas de test, les essais sont reproductibles (car repartent toujours de la même base) et la base de données initiale n'est pas altérée.
Si vous préférez travailler directement sur la base de données, vous pouvez directement y accéder en plaçant l'emplacement du fichier comme paramètre de la fonction
connectavec comme code, par exemple,bdd = sqlite3.connect(ma_base_de_donnees.db) -
-
Les lignes 21 et 51
bdd.commit()servent à valider les modifications faites sur la table : celle-ci est dès lors modifiée.Il est possible de revenir à l'état précédent la dernière modification issue d'un
commitavec l'instructionbdd.rollback(). Ainsi, les modifications dues à ce commit sont annulées et perdues. -
À la ligne 6 dans
cur = bdd.cursor(),cursorest une méthode qui permet de créer un objetcur(un "curseur") à partir de la base de données importées sous l'objetbdd.
C'est sur cet objetcurque les requêtes s'appliquent, non pas directement sur l'objetbdd. -
Pour exécuter une requête sur un objet de type "curseur", il suffit d'appliquer la méthode
executesuivi du code en langage SQL écrit entre des'''. (cf. le code des lignes 10 à 19)Pour exécuter une requête multiple sur un objet de type "curseur", il suffit d'appliquer la méthode
executeavec deux paramètres, comme lors des lignes 48 et 49 aveccur.execute("""INSERT INTO `Artiste` (`idArtiste`, `nom`, `prénom`, `annéeNaiss`) VALUES(?,?,?,?) """,donnees):-
le premier correspond à la requête en langage SQL où l'opérateur
?est utilisé, -
le second est un tuple dont les éléments servent de paramètres à la requête grâce à l'opérateur
?.
-
Le langage SQL et la création de tables
Pour créer une table, on utilise les mots clés CREATE TABLE. La syntaxe est :
CREATE TABLE nom_table( attribut_1 domaine_1 contrainte_1,
attribut_2 domaine_2 contrainte_2,
...
attribut_n domaine_n contrainte_n,
...
contrainte_globale);
-
le langage SQL est insensible à la casse,
-
dans un script, si vos utilisez plusieurs commandes SQL, il faut écrire un
;à la fin de chaque ordre, -
une convention d'écriture : écrire le nom des tables au singulier,
-
les contraintes pour les attributs et les contraintes globales ne sont pas obligatoires.
Reprenez le Trinket ci-dessus et répondez aux questions suivantes :
-
Quelles sont les contraintes des différents attributs ?
-
Existe-t-il une contrainte globale ?
les types de données en langage SQL
- Il existe différents types de données dans le langage SQL :
- les types numériques
- les types textes
- le type booléen
- les dates et durées
| Nom du type/mot clé | Description |
|---|---|
| SMALLINT | Entier de 16 bits signés (valeur exacte) |
| INTEGER | Entier de 32 bits signés (valeur exacte) |
| INT | Alias pour INTEGER |
| BIGINT | Entier de 64 bits signés (valeur exacte) |
| DECIMAL(t,f) | Décimal signé de t chiffres dont f chiffres après la virgule (valeur exacte) |
| REAL | Flottant de 32 bits (valeur approchée) |
| DOUBLE PRECISION | Flottant de 32 bits (valeur approchée) |
| CHAR(n) | Chaîne de $n$ caractères |
| VARCHAR(n) | Chaîne d'au plus $n$ caractères |
| TEXT | Chaîne de taille quelconque |
| BOOLEAN | Type booléen parfois non supporté |
| DATE | Date au format 'AAAA-MM-JJ' |
| TIME | Heure au format 'hh:mm:ss' |
| TIMESTAMP | Un instant (date et heure) au format 'AAAA-MM-JJ hh:mm:ss' |
| NULL | Il existe une valeur NULL (comme None en Python) |
SQL et la gestion des contraintes d'intégrité
Nous avons vu le caractère indispensable des contraintes d'intégrité dans le modèle relationnel. Voici la liste des mots clés qui permettent d'implémenter ces contraintes :
| Nom | Mot-clé | Explications |
|---|---|---|
| Clé primaire | PRIMARY KEY | idEleve INT PRIMARY KEY (lors de la déclaration de l'attribut) ou PRIMARY KEY(idEleve) (lors des contraintes globales) |
| Clé étrangère | REFERENCES nom_table (parfois avec FOREIGN KEY) | Nom_attribut domaine_ attribut REFERENCES nom_table (nom_attribut) |
| Unicité d'un attribut | UNIQUE | Parfois utiliser pour un attribut qui n'est pas une clé primaire (une adresse email par exemple). |
| Obliger à la non nullité | NOT NULL | Pour un nom par exemple. |
| Contrainte utilisateur | CHECK | Par exemple pour imposer un âge positif (ou la majorité). Se déclare dans les contraintes globales. Exemple : CHECK (age >=0) |
SQL et la suppression de tables
La commande qui permet de supprimer une table est la commande DROP TABLE nom_table.
Il faut faire attention aux contraintes de référencement sous peine d'avoir un message d'erreur qui spécifie que la suppression n'a pas été effectuée. Cela arrive lorsque votre table sert de référence pour une clé étrangère dans une autre table.
SQL et l'insertion dans une table
Maintenant que nos tables sont créées, il faut insérer des valeurs ($n$-uplets).
Pour insérer des valeurs, nous utiliserons la commande INSERT INTO nom_table VALUES (n-uplets).
Les contraintes d'intégrité sont vérifiées au moment de l'insertion.
Reprenez l'exercice Trinket en langage Python et repérer toutes les informations de ce cours et la manière dont Python gère les ordres SQL.
Exercices
En utilisant Trinket ou votre IDLE préféré, réaliser une base de données dans laquelle des personnes (nom et prénom) sont associées à leur numéro de téléphone. Vous pouvez réaliser une base simple avec la création d'une seule table (personne) ou compliquer un peu les choses avec la création de deux tables (personne et numéros). Vous insérerez quelques enregistrements dans votre base de données.
Cet exercice vous permet de tester les contraintes d'intégrité. Le fichier Jupyter est téléchargeable en fin de documents.
Fichier Jupyter à téléchargerRevenez sur votre base de données series et reprenez votre schéma relationnel. Implémentez ce schéma par l'API sqlite3 du langage python. enregistrez quelques $n$-uplets dans votre base.
Accéder à une base de données en utilisant un SGBD
Il existe différentes méthodes pour accéder à une base de données par l'intermédiaire d'un SGBD
Bases accessibles sur un serveur hébergé sur le web
Pour avoir des exemples de requêtes, vous pouvez visiter cet espace pédagogique du cnam (conservatoire national des arts et métiers)
Base de données en français avec des exemples de requêtes sur le CNAMTester de nombreuses requêtes pour vous familiariser avec langage (que nous utiliserons dans bdd3)
Mode client-serveur sur votre propre environnement
Il faut créer un environnement qui permette d'utiliser le modèle client-serveur avec un client et un serveur sur votre ordinateur.
Cet environnement est constitué de différents outils :
- Un langage utilisé par les serveurs : le langage php
- Un logiciel de serveur web qui permettra à votre ordinateur de se comporter comme un serveur hébergé sur le web : apache
- Un SGBD : mysql
- Une application web de gestion pour les données de mysql : phpMyadmin
Il existe des suites logicielles qui installent ces outils.
Nous allons utiliser le logiciel UwAmp : lien vers le site
Il faut installer ce logiciel sur votre ordinateur.
Installation et configuration de UwAmp
Il faut configurer UwAmp pour qu'il s'installe comme tache de fond, visible dans la barre des taches.
Une fois que les serveurs sont démarrés, et que les ports sont configurés, il faut démarre l'outil PHPMyAdmin.
- Quelques impressions écrans :
- La fenêtre principale avec les serveurs démarrés
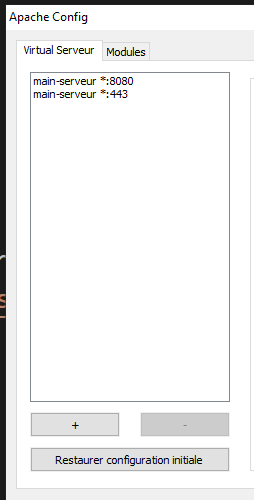
- La configuration des ports du serveur Apache :
- La fenêtre de connexion de phpMyAdmin
Téléchargement des bases pour travailler
Quelques bases à télécharger pour vous entraîner.
- Liste :
- Base avec des $n$-uplets : Films
- Base sans $n$-uplets : series
- Base avec $n$-uplets : tournoi
- Base avec $n$-uplets (développée dans la cadre du DIU de Reims) : Santé
- Base avec $n$-uplets (utilisée dans la cadre du DIU de Reims) : blanchisserie
Quelques bases accessibles sur le web :
- Liste :
- Base (format csv) française : Jeux de données
- Base mondiale à télécharger : Jeux de données mondiales
Utilisation de phpMyAdmin
Vous devez une fois connecté à phpMyAdmin avoir une fenêtre qui ressemble à : 
Une première vidéo de prise et main pour importer une base déjà construite.
Choisir un base dans le chapitre "Téléchargement des bases pour travailler" et l'importer à l'aide phpMyadmin.
Vous avez déjà travaillé une requête par l'intermédiaire de l'api sqlite3.
Vous pouvez maintenant écrire et exécuter des requêtes dans phpMyadmin. Vous pouvez vous aider de la vidéo suivante,
par exemple pour, dans la table film, faire afficher l'ensemble des lignes, puis
seulement l'ensemble des titres de films avec leur genre et leur code pays présents dans la base de données :
Une vidéo pour créer votre première base pour faire des tests.
Quelques requêtes intéressantes sur la création d'utilisateurs avec des droits particuliers.
- Créer un utilisateur avec un mot de passe :
CREATE USER 'nouveau_utilisateur'@'localhost' IDENTIFIED BY 'mot_de_passe';
- Lui attribuer tous les privilèges pour toutes les bases :
GRANT ALL PRIVILEGES ON * . * TO 'nouveau_utilisateur'@'localhost';
- A la place de
ALL PRIVILEGES, on peut utiliserCREATE(créer),SELECT(sélectionner),UPDATE(mettre à jour),DELETE(effacer),INSERT(insérer),DROP(supprimer) - Exemple d'attribution des privilèges créer, sélectionner et insérer :
GRANT CREATE, SELECT ON * . * TO 'nom_utilisateur'@'localhost';
- DE la même manière on peut remplacer
GRANTparREVOKEpour révoquer des privilèges. - Exemple de révocation de tous les privilèges :
REVOKE ALL PRIVILEGES ON *.* FROM 'nom_utilisateur'@'localhost';
- La commande
DROPmérite votre attention car la suppression est définitive. - Exemple de suppression d'un utilisateur :
DROP USER ‘nom_utilisateur’@‘localhost’;
Si vous êtes en ligne de commandes, il faut penser à utiliser la commande
FLUSH PRIVILEGES
DROP est désactivéeUn lien intéressant avec les commandes principales : Lien vers le site
A l'aide des commandes précédentes, vous devez créer des utilisateurs avec des profils particuliers :
- Un utilisateur qui n'a que le droit de consultation de la base.
- Un utilisateur qui a les droits de création.
- Un utilisateur qui a tous les droits sauf celui de supprimer.
- A vous d'inventer.
Faire des essais en vous connectant avec ces différents profils
Utiliser SQL en ligne de commande
Il peut être intéressant d'interroger et de travailler sur sa base en mode console.
- Quelques impressions écrans :
- Chemin, connexion et choix d'une base :
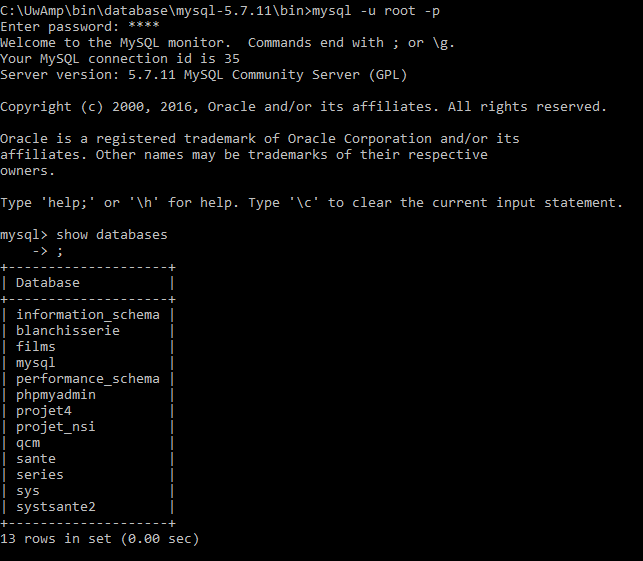
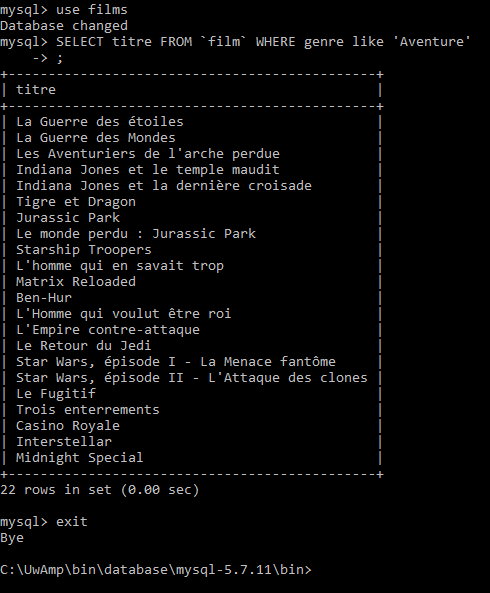
- Une requête et déconnexion :
Quelques commandes intéressantes :
| Commande | Explications |
|---|---|
| mysql -u root -p | Se connecter à MySQl avec l'utilisateur root |
| source chemin_source | Importer une base. Commande intéressante si la base est 'lourde' et ne passe pas en mode graphique. |
| Show databases | Affichage des bases |
| use nom_base | Connexion à la base |
| exit | Quitter MySQL |
Se connecter à Mysql en ligne de commandes
Attention vous ne devez pas laisser les bases que vous avez téléchargées dans Téléchargement(download), car il se trouve lui même dans le dossier Elève qui est écrit avec un accent, ce qui est bloquant. Je vous conseille de mettre vos tables directement dans le dossier UwAmp.
- Vérifier la présence de bases.
- Se connecter à une base. Vérifier les tables de cette base. Faire une requête sur une table (exemple
select * from table;) - Importer en ligne de commandes une base du chapitre "Téléchargement des bases pour travailler"
Un lien intéressant avec les commandes principales : Lien vers le site
Interrogée une base de données en ligne de commande sur un serveur Linux distant (raspberry)
Dans un premier temps, demander à votre professeur l'adresse IP du Raspberry ainsi que des identifiants et mot de passe.
Ouvrer un terminal "invite de commandes" de windows (Vous pouvez également utiliser l'application Putty)
La commande ssh nom_utilisateur@adresse_ip
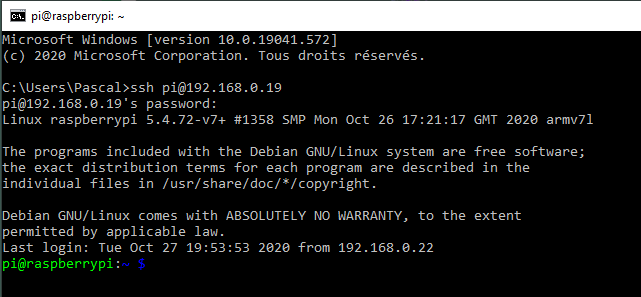
Connexion à mysql avec un utilisateur 'eleve'
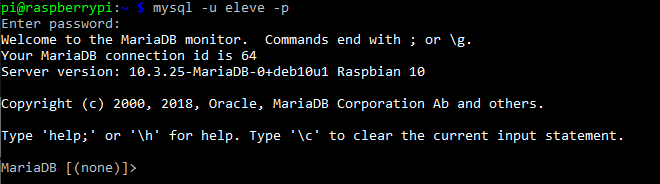
Un utilisateur 'utilisateur' avec MDP 'utilisateur' a été créé avec des privilèges restreints pour une utilisation de toutes les bases.
Utilisation de vscode
Vscode peut vous permette d'accéder à vos bases de données. Il faut installer quelques extensions.
Vscode peut également vous permette de lire les fichiers SQL.
Prendre un ou plusieurs fichiers disponibles dans "Téléchargement des bases pour travailler" ( accès direct) et les ouvrir avec Vscode.
Observer la structure de la base de données ainsi que son contenu.
Modifier le contenu d'une base de données dans Vscode et réimporter la base avec la méthode de votre choix.
Faire des requêtes pour observer les modifications.
Bibliographie et sitographie
- "Numérique et sciences informatiques" - "Compétences attendues" - ellipses -
- "Numérique et sciences informatiques" - "24 leçons avec exercices corrigés" - ellipses -
- "Numérique et sciences informatiques" - "Prépas sciences" - ellipses -
Savoir et Savoir faire
- Identifier les contraintes d'intégrité dans les ordres du langage SQL
- Repérer les anomalies dans le schéma d'une base de données
- Insérer des $n$-uplets dans une table
- Se connecter à une base de données en utilisant un SGBD
- Identifier les services principaux d'un SGBD
- Savoir distinguer la structure d’une base de données de son contenu

Les différents
auteurs mettent l'ensemble du site à disposition selon les termes de la licence Creative
Commons Attribution - Pas d’Utilisation Commerciale - Partage dans les Mêmes Conditions 4.0
International