Aujourd'hui des quantités énormes de données sont produites chaque jour. L'informatique en permet le traitement .
Même si il existe des logiciels spécialisés, les logiciels de gestion de bases de données (SGBD) que nous étudierons en terminale, le langage de programmation python nous permet de lire, d'écrire, ou de traiter des données structurées notamment au format CSV.
Demandez le programme !
Le format csv
Définition du format csv
Le format CSV (pour Comma Separated Values,
soit en français Valeurs Séparées par des Virgules) est un format très utilisé pour représenter des données structurées, notamment pour importer ou exporter des
données à partir d'une feuille de calculs d'un tableur.
C'est un fichier texte dans lequel chaque ligne correspond à une ligne du tableau.
Dans le format CSV, chaque ligne représente un enregistrement
c'est à dire une structure de données,
données pouvant être de types différents et auxquelles on accède grâce à un nom (appelé aussi critère).
Sur une même ligne, les différents champs de l’enregistrement sont séparés
dans le monde anglo-saxon par une virgule (d’où le nom).
D'autres caractères peuvent être utilisés comme le point-virgule ;, l'espace ou la tabulation \t.
Chaque élément de la première ligne est appelé un descripteur ou nom de champ. Cette première ligne est appelée l'en-tête.
Chaque colonne est appelé un champ
Chaque case est appelée une valeur.
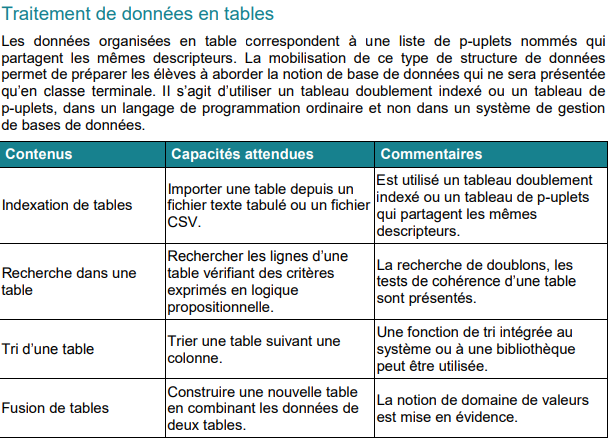
Exemple de feuille de calculs
Fichier csv correspondant

En Python, un enregistrement peut-être représenté par un dictionnaire.
En Python, un fichier csv par peut-être représenté une liste de dictionnaires, dont les clés sont les descripteurs de chaque champ.
On reprend le fichier csv de l'exemple précédent :
-
Le premier enregistrement peut être représenté par :
{'Nom': 'Baron', 'Prénom': 'Paul', 'NSI': '18', 'Physique': '16', 'Maths': '15'} -
Le contenu du fichier complet peut être représenté par :
ma_table = [{'Nom': 'Baron', 'Prénom': 'Paul', 'NSI': '18', 'Physique': '16', 'Maths': '15'}, {'Nom': 'Taillant', 'Prénom': 'Greg', 'NSI': '1', 'Physique': '3', 'Maths':'5'}, {'Nom': 'Gourdy', 'Prénom': 'Zoé', 'NSI': '14', 'Physique': '13', 'Maths': '16'}]
Import d'un fichier csv : les fonctions reader et Dictreader
L'objectif de cette partie est d'apprendre à importer un fichier csv en Python. C'est à dire à lire un fichier csv en vue de le manipuler.
Import d'un fichier csv
La bibliothèque csv implémente des classes pour lire des données tabulaires au format CSV
La fonction reader() du module csv renvoie un objet de type csv.reader qui est itérable. Chaque élément de cet objet est une liste.
La fonction DictReader du module csv renvoie un objet de type csv.DictReader itérable aussi.
Chaque élément de cet objet est un dictionnaire ordonné : c'est un dictionnaire qui mémorise l'ordre d'insertion des clés.
Les éléments de la première ligne du fichier csv (les noms de champ ou descripteur) se retrouvent
être les clés de ce dictionnaire.
fichier csv à télécharger et à installer dans le répertoire courant de travail de l'IDE utilisé.
Utilisation de la fonction Reader.
import csv # le module pour les fichiers csv
file = open("test.csv", "r") # ouvrir le fichier
csv_en_liste = csv.reader(file, delimiter=",") # initialisation d’un lecteur de fichier ; delimiter est facultatif
for ligne in csv_en_liste : # parcours du lecteur avec une boucle
print(ligne) # affichage ligne à ligne
file.close() # fermeture du fichier Utilisation de la fonction DictReader et obtention de dictionnaires.
import csv # le module pour les fichiers csv
file = open("test.csv", "r") # ouvrir le fichier
csv_en_dico = csv.DictReader(file, delimiter=",") # initialisation d’un lecteur de fichier avec création automatique de dictionnaire
for ligne in csv_en_dico: # parcours du lecteur avec une boucle
print(dict(ligne)) # affichage ligne à ligne
file.close() # fermeture du fichier Les données d'un fichier csv sont généralement stockées dans une liste
En vous aidant de de l'exemple 3 précédent,
proposer fonction csv_en_list_de_list(nom) où nom
est une chaine de caractères qui renvoie une liste de la liste obtenue avec la fonction reader.
-
par extension.
-
par compréhension.
Tester dans chacun des cas la fonction csv_en_list_de_list
avec ce fichier csv à télécharger
et à installer dans le répertoire courant de travail de l'IDE utilisé.
csv_en_list_de_list("test") doit renvoyer la liste suivante :
[['nom', 'prenom', 'age'], ['Dupont', 'Jean-Claude', '32'], ['Duteil', 'Paul', '41'],\
['Claudon', 'Goery', '37'], ['Tonton', 'Pierre', '54'], ['Penard', 'Bob', '18'],\
['Herpoix', 'Stephane', '55'], ['Salicorne', 'Bruno', '15'], ['Poiteau', 'Maxe', '33'],\
['Clanget', 'Gilles', '54'], ['Luillier', 'Martin', '34'], ['Clanget', 'Justine', '14']\
['Gillier', 'Paul', '16']]
Le symbole \ permet de continuer une instruction sur plusieurs lignes
en indiquant une rupture de ligne explicite, notamment pour des expressions
longues comme cette liste, sans introduire une nouvelle instruction.
Cet exercice est important pour la suite vu son utilité.
En vous aidant de de l'exemple 4 précédent,
proposer une fonction impor(nom) qui reçoit un paramètre nom de type chaîne de caractères qui est le
nom du fichier csv sans l'extension et qui retourne une liste de dictionnaires
qui contient les informations du fichier csv.
Tester la fonction impor
avec le fichier précédent.
impor("test") doit renvoyer la liste de dictionnaires suivante :
[{'nom': 'Dupont', 'prenom': 'Jean-Claude', 'age': '32'}, {'nom': 'Duteil', 'prenom': 'Paul', 'age': '41'}, \
{'nom': 'Claudon', 'prenom': 'Goery', 'age': '37'}, {'nom': 'Tonton', 'prenom': 'Pierre', 'age': '54'}, \
{'nom': 'Penard', 'prenom': 'Bob', 'age': '18'}, {'nom': 'Herpoix', 'prenom': 'Stephane', 'age': '55'},\
{'nom': 'Salicorne', 'prenom': 'Bruno', 'age': '15'}, {'nom': 'Poiteau', 'prenom': 'Maxe', 'age': '33'}, \
{'nom': 'Clanget', 'prenom': 'Gilles', 'age': '54'}, {'nom': 'Luillier', 'prenom': 'Martin', 'age': '34'}, \
{'nom': 'Clanget', 'prenom': 'Justine', 'age': '14'}, {'nom': 'Gillier', 'prenom': 'Paul', 'age': '16'}]-
C'est cette fonction que l'on peut considérer comme l'importation d'une table csv en Python.
-
Au vu de la première partie, c'est la fonction
DictReader()qu'il faut favoriser afin d'avoir une représentation des données attendues.
La commande with open(...) as ...
Il existe en Python une commande qui permet d'ouvrir un fichier csv sans obligation de le fermer à la fin de l'exécution puisque la commande gère la fermeture.
with open(nom_du_fichier, 'r') as sortieIci on ouvre le fichier nom_du_fichier en lecture et on stocke cette ouverture dans la variable sortie.
On pourra remplacer le "r" par "w" pour écrire
dans le fichier.
Export d'un fichier csv
Maintenant nous savons ouvrir un fichier csv en Python, l'objectif de cette partie est de comprendre comment on exporte un fichier csv à partir de Python.
Une situation classique serait :
-
l'ouverture d'un fichier csv avec Python (c'est la partie importation) ; on obtient une table de données.
-
Ensuite, on modifie le fichier de la table de données.
-
Enfin, on enregistre les modifications dans un fichier csv (c'est la parti exportation).
Voyons dans l'exemple suivant comment créer un fichier csv correspondant à une table donnée.
Conversion d'une table en fichier csv
Pour l'exemple, nous allons travailler avec cette table :
table_exemple = [{'nom': 'Dupont', 'prenom': 'Jean-Claude', 'age': '32'},
{'nom': 'Duteil', 'prenom': 'Paul', 'age': '41'},
{'nom': 'Claudon', 'prenom': 'Goery', 'age': '37'},
{'nom': 'Tonton', 'prenom': 'Pierre', 'age': '54'},
{'nom': 'Penard', 'prenom': 'Bob', 'age': '18'},
{'nom': 'Herpoix', 'prenom': 'Stephane', 'age': '55'},
{'nom': 'Salicorne', 'prenom': 'Bruno', 'age': '15'},
{'nom': 'Poiteau', 'prenom': 'Maxe', 'age': '33'},
{'nom': 'Clanget', 'prenom': 'Gilles', 'age': '54'},
{'nom': 'Luillier', 'prenom': 'Martin', 'age': '34'},
{'nom': 'Clanget', 'prenom': 'Justine', 'age': '14'},
{'nom': 'Gillier', 'prenom': 'Paul', 'age': '16'}]
Voilà la fonction qui va permettre de créer un fichier csv portant le nom
table_exemple.csv correspondant à la table précédente.
def vers_csv(nom_de_la_table, ordre, nom_du_fichier_csv):
"""
nom_de_la_table doit être une liste de dictionnaires
ordre doit être une liste des clés des dictionnaires qui imposera l'ordre des champs du fichier csv
nom_du_fichier_csv est une chaîne de caractères donnant le nom du fichier créé sans précisé l'extension
"""
table = nom_de_la_table
with open(nom_du_fichier_csv + '.csv', "w", newline='') as fic: # newline='' permet d' éviter des lignes vides indésirables
dic = csv.DictWriter(fic, fieldnames=ordre) # Création d'un objet DictWriter dont l'ordre des descripteurs est imposé
dic.writeheader() # permet d'ajouter la ligne d'en-tête du fichier csv.
for ligne in table:
dic.writerow(ligne) # rajout de chaque enregistrement : un par ligne.
return None -
Cette procédure
vers_csv()est très importante. -
Il faut comprendre l'ensemble des lignes commentées de ce script.
Tester le code de l'exemple 6 précédent en faisant en
sorte que le contenu de la variable table_exemple corresponde
aux différents enregistrements du fichier table_exemple.csv,
fichier qui sera créé par défaut dans le répertoire courant de travail
de l'IDE utilisé.
L'objectif de cet exercice est d'obtenir un outil qui permet d'insérer un nouvel enregistrement dans un fichier csv.
-
Ouvrir le fichier csv à télécharger précédent et l'installer dans le répertoire courant de travail de l'IDE utilisé.
-
Repérer le nom et l'ordre des descripteurs qui serviront de clés aux dictionnaires.
Écrire une fonction
ajout(fichier)qui va proposer au lecteur(grâce à la fonctioninput) l'implémentation d'un nouvel enregistrement.
Le paramètrefichierest une chaîne de caractères correspondant au nom du fichier csv à modifier (sans préciser le format donc sans l'extension" .csv").Utiliser la fonction
imporde l'exercice 2 permet d'importer facilement le contenuUtiliser la fonction
vers_csvde l'exemple 6 permet d'exporter facilement le contenu dans un fichier de format csv.-
Tester cette fonction avec l'enregistrement correspondant à
Danlta Alphonsequi a eu dans l'ordre des matières 15, 16 et 11.
Opérations sur les tables
Dans cette deuxième partie, nous utiliserons les fonctions d'importation
et d'exportation précédentes impor et vers_csv.
Sélectionner des enregistrements suivant certains critères
Ici nous utiliserons le principe des listes par compréhension où nous ajouterons une comparaison :
resultats = impor('table_exemple') # resultats est une liste de dictionnaires
select_nom = [p for p in resultats if p['nom'] == 'Clanget']
print(select_nom) Lors de la création de notre liste select_nom par compréhension, on ajoute seulement les enregistrements dont le champ nom correspond à 'Clanget'.
Cette variable select_nom contient à l'issue de l'exécution :
[{'nom': 'Clanget', 'prenom': 'Gilles', 'age': '54'}, {'nom': 'Clanget', 'prenom': 'Justine', 'age': '14'}].
Dans cet exercice, vous utiliserez ce fichier csv, celui de l'exemple 6 et de l'exercice 3, que vous avez normalement déjà installé dans le répertoire courant de l'IDE utilisé.
-
En s'aidant du script de l'exemple précédent, écrire une fonction
un_critere(nom_du_fichier_csv, nom_du_champ, valeur_a_chercher)qui extrait les enregistrements dont le champ nom_du_champ estvaleur_a_chercher.Exemples de test :
>>>un_critere('table_exemple', 'nom', 'Clanget') [{'nom': 'Clanget', 'prenom': 'Gilles', 'age': '54'}, {'nom': 'Clanget', 'prenom': 'Justine', 'age': '14'}] >>>un_critere("table_exemple", "age", "54") [{'nom': 'Tonton', 'prenom': 'Pierre', 'age': '54'}, {'nom': 'Clanget', 'prenom': 'Gilles', 'age': '54'}] -
Écrire une fonction
deux_criteres_ou(nom_du_fichier_csv, nom_du_champ1, valeur_a_chercher1, nom_du_champ2, valeur_a_chercher2)qui extrait les enregistrements dont le champnom_du_champ1estvaleur_a_chercher1ou dont le champ nom_du_champ2 estvaleur_a_chercher2.Exemple de test :
>>>deux_criteres_ou("table_exemple", "nom", "Clanget", "prenom", "Paul") [{'nom': 'Duteil', 'prenom': 'Paul', 'age': '41'}, {'nom': 'Clanget', 'prenom': 'Gilles', 'age': '54'}, {'nom': 'Clanget', 'prenom': 'Justine', 'age': '14'}, {'nom': 'Gillier', 'prenom': 'Paul', 'age': '16'}] -
Écrire une fonction
deux_criteres_et_non(nom_du_fichier_csv, nom_du_champ1, valeur_a_chercher1, nom_du_champ2, valeur_a_chercher2)qui extrait les enregistrements dont le champnom_du_champ1estvaleur_a_chercher1et qui ne contient pas dans le second champnom_du_champ2la valeurvaleur_a_chercher2.Exemple de test :
>>>deux_criteres_et_non("table_exemple", "nom", "Clanget", "prenom", "Justine") [{'nom': 'Clanget', 'prenom': 'Gilles', 'age': '54'}] -
Écrire une fonction
deux_criteres_ou_non(nom_du_fichier_csv, nom_du_champ1, valeur_a_chercher1, nom_du_champ2, valeur_a_chercher2)qui extrait les enregistrements dont le champnom_du_champ1estvaleur_a_chercher1ou qui ne contient pas dans le second champnom_du_champ2la valeurvaleur_a_chercher2.Exemple de test :
>>>deux_criteres_ou_non("table_exemple", "nom", "Clanget", "age", "54") [{'nom': 'Dupont', 'prenom': 'Jean-Claude', 'age': '32'}, {'nom': 'Duteil', 'prenom': 'Paul', 'age': '41'}, {'nom': 'Claudon', 'prenom': 'Goery', 'age': '37'}, {'nom': 'Penard', 'prenom': 'Bob', 'age': '18'}, {'nom': 'Herpoix', 'prenom': 'Stephane', 'age': '55'}, {'nom': 'Salicorne', 'prenom': 'Bruno', 'age': '15'}, {'nom': 'Poiteau', 'prenom': 'Maxe', 'age': '33'}, {'nom': 'Clanget', 'prenom': 'Gilles', 'age': '54'}, {'nom': 'Luillier', 'prenom': 'Martin', 'age': '34'}, {'nom': 'Clanget', 'prenom': 'Justine', 'age': '14'}, {'nom': 'Gillier', 'prenom': 'Paul', 'age': '16'}] -
Écrire une fonction
un_critere_depasse(nom_du_fichier_csv, nom_du_champ, valeur_a_depasser)qui extrait les enregistrements dont le champnom_du_champa une valeur qui dépasse la valeurvaleur_a_depasser.Exemple de test :
>>>un_critere_depasse('table_exemple', 'age', '41') [{'nom': 'Tonton', 'prenom': 'Pierre', 'age': '54'}, {'nom': 'Herpoix', 'prenom': 'Stephane', 'age': '55'}, {'nom': 'Clanget', 'prenom': 'Gilles', 'age': '54'}]
Sélectionner des colonnes
Nous allons continuer à travailler sur le même fichier tablea_exemple.csv et à utiliser le principe des listes par compréhension.
Dans cette partie, le but est sélectionner seulement un ensemble de colonnes (c'est-à-dire de champs) du fichier csv.
L'exemple qui sui est plus complexe : vérifiez que la deuxième ligne de code
est bien claire pour vous :
resultats = impor('table_exemple') # resultats est une liste de dictionnaires
select_colonne = [{cle: ligne[cle] for cle in ligne if cle in ['nom', 'age']} for ligne in resultats]
print(select_colonne) Lors de la création par compréhension de la liste de dictionnaires resultats,
on ajoute seulement les champs "nom" et "age de chaque enregistrement.
L'exécution du code précédent conduit à l'affichage de la liste suivante :
[{'nom': 'Dupont', 'age': '32'},
{'nom': 'Duteil', 'age': '41'},
{'nom': 'Claudon', 'age': '37'},
{'nom': 'Tonton', 'age': '54'},
{'nom': 'Penard', 'age': '18'},
{'nom': 'Herpoix', 'age': '55'},
{'nom': 'Salicorne', 'age': '15'},
{'nom': 'Poiteau', 'age': '33'},
{'nom': 'Clanget', 'age': '54'},
{'nom': 'Luillier', 'age': '34'},
{'nom': 'Clanget', 'age': '14'},
{'nom': 'Gillier', 'age': '16'}]Écrire une fonction projection qui reçoit en paramètres le nom d'un fichier csv (sans son extension ".csv" ) et une liste d'attributs, fonction qui retourne une liste de dictionnaires dont les clés sont uniquement ces attributs.
Exemple de test :
>>>projection("table_exemple", ["age", "nom"])
[{'nom': 'Dupont', 'age': '32'},
{'nom': 'Duteil', 'age': '41'},
{'nom': 'Claudon', 'age': '37'},
{'nom': 'Tonton', 'age': '54'},
{'nom': 'Penard', 'age': '18'},
{'nom': 'Herpoix', 'age': '55'},
{'nom': 'Salicorne', 'age': '15'},
{'nom': 'Poiteau', 'age': '33'},
{'nom': 'Clanget', 'age': '54'},
{'nom': 'Luillier', 'age': '34'},
{'nom': 'Clanget', 'age': '14'},
{'nom': 'Gillier', 'age': '16'}] Tri d'une table sur une colonne
Une table étant représentée par une liste, on peut la trier en utilisant la fonction
sorted ou la méthode .sort(), avec l’argument supplémentaire key qui est une fonction renvoyant la valeur utilisée pour le tri.
Rappel :
la méthode .sort() trie la liste en place,
c'est-à-dire modifie la liste directement sans en créer une nouvelle,
alors que la fonction sorted() renvoie une nouvelle liste
correspondant la liste triée, la liste initiale étant laissée intacte.
Pour la suite nous utiliserons la fonction sorted().
On peut trier les chaînes de caractères selon différents critères :
-
L'ordre lexicographique. Par exemple :
['aaa', 'bb']. -
La longueur de l'élément. Par exemple :
['bb', 'aaa'].
>>>lst = sorted(['aaa', 'bb'])
>>>print(lst)
['aaa', 'bb'] # le tri se fait par défaut suivant l'ordre lexicographique
>>>lst = sorted(['aaa', 'bb'], key=len)
>>>print(lst)
['bb', 'aaa'] # le tri s'est fait ici suivant la longueur des chaînes de caractères contenues.
L'attribut key, nous permet de choisir le critère de tri,
ici len pour trier par ordre croissant suivant la longueur
de la chaîne de caractères considérée.
Rechercher sur la
la documentation officielle de Python le type de valeurs que peut prendre l'attribut key.
Afin de faciliter le tri par colonne, nous allons introduire la fonction lambda
Une fonction lambda est une fonction anonyme, c'est en quelque sorte une fonction pouvant
être écrite en une seule ligne.
On la note ainsi :
lambda entree : expression de la sortieVoici un exemple :
Afin de bien comprendre la structure d'une fonction lambda, testez les deux fonctions
f et gcréées ci-dessous dans une console pour x=4 :
def f(x):
return x*2
g = lambda x : x*2
Dans l'exemple ci-dessous, nous allons trier la table par la note de NSI, le nom de la variable lycéen n'ayant pas d'importance :
ma_table = [{'Nom': 'Baron', 'Prenom': 'Paul', 'NSI': '18', 'Physique': '16', 'Maths': '15'},
{'Nom': 'Taillant', 'Prenom': 'Greg', 'NSI': '1', 'Physique': '3', 'Maths': '5'},
{'Nom': 'Gourdy', 'Prenom': 'Zoé',' NSI':' 14', 'Physique': '13', 'Maths': '16'}]
table_triee = sorted(ma_table, key=lambda lyceen : lyceen["NSI"])
print (table_triee) Dans cet exercice, vous réutiliserez le fichier table_exemple.csv déjà téléchargé et utilisé lors de l'exercice 5.
-
Importer le contenu du fichier
table_exemple.csv, trier la table obtenue par âge croissant, puis enregistrer dans un fichiertable_age_croi.csv.Utiliser les fonction déjà créée
imporetvers_csvafin de faciliter l'importation et l'exportation vers un csv. -
Importer le contenu du fichier
table_exemple.csv, trier la table obtenue par âge décroissant, puis enregistrer dans un fichiertable_age_decroi.csv.
Plutôt que d'utiliser la méthode reverse() pour inverser
sur place l'ordre d'une liste, il est possible d'utiliser dans
la fonction sorted l'attribut reverse avec
comme valeur True.
Ainsi, on peut trier dans l'exercice précédent la liste resultats
avec : sorted(resultats, key=lambda lyceen : str(lyceen["age"]), reverse=True)
Écrire une fonction tri(table, attribut, decroit=False) qui trie une table table de type list selon l'attribut attribut de manière croissante dans le cas général et de manière décroissante s'il on écrit True comme troisième argument.
Jointure de table
Jointure de deux tables selon un champ
La jointure de deux tables selon un champ est une table contenant les enregistrements des valeurs communes correspondant au champ de deux tables.
On considère les deux tables suivantes :
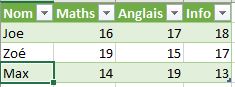
pour_jointure_tab1.csv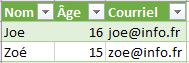
pour_jointure_tab2.csvLa jointure de ces deux tables suivant le champ "Nom" est :

Fonction fusion
Voilà un script de la fonction fusion qui réalise la jointure de deux tables
selon la clé cle supposée commune aux deux tables.
def fusion(table1, table2, cle):
table_fusion = [] # table réponse créée
for ligne1 in table1: # balayage de la première table par ses enregistrements
for ligne2 in table2: # balayage de la seconde table par ses enregistrements
# cle est supposée être une clef commune aux deux dictionnaires :
if ligne1[cle] == ligne2[cle]: # cas d'une valeur identique aux deux tables
new_ligne = ligne1 # début de l'enregistrement fusionné en prenant le premier dictionnaire en entier
for key in ligne2: # balayage du seconde dictionnaire
if key != cle:
new_ligne[key] = ligne2[key] # rajout des associations du second dictionnaire
table_fusion.append(new_ligne) # rajout à la table de l'enregistrement complet
return table_fusion -
Écrire une fonction
fusion2(table1, table2, cle1, cle2=None)oùcle1est une clef de la tabletable1, oùcle2est une clef de la tabletable2.
On suppose quecle1n'est pas forcément danstable2mais serait équivalente àcle2; par exemplecle1pourrait s'appelernamedans la premièretable1et correspondre à celle s'appelantnomdans la tabletable2. -
Pour tester la fonction
fusion2, télécharger et installer dans le répertoire courant de travail de l'IDE utilisé les deux tables suivantes : table1 de l'exemple précédent et table2 de l'exemple précédent.
Vérifier que les différentes instructions suivantes conduisent bien à l'affichage final correspondant à la table fusionnée représentée dans l'exemple précédent :
>>>table1 = impor("pour_jointure_tab1")
>>>table2 = impor("pour_jointure_tab2")
>>>fusionnee = fusion2(table1, table2, "Nom")
>>>print(fusionnee)
[{'Nom': 'Joe', 'Anglais': '17', 'Maths': '16', 'NSI': '18', 'Age': '16', 'Courriel': 'joe@info.fr'},
{'Nom': 'Ursula', 'Anglais': '15', 'Maths': '19', 'NSI': '17', 'Age': '15', 'Courriel': 'ursula@info.fr'}]Générateur aléatoire de questions sur ce chapitre
Il faut actualiser la page pour changer de question. Propriétaire de la ressource : le site GeNumsi en licence CC BY_NC-SA

Les différents
auteurs mettent l'ensemble du site à disposition selon les termes de la licence Creative
Commons Attribution - Pas d’Utilisation Commerciale - Partage dans les Mêmes Conditions 4.0
International