Le développement des traitements informatiques nécessite la manipulation de données de plus en plus nombreuses. Leur organisation et leur stockage constituent un enjeu essentiel de performance. Le recours aux bases de données relationnelles est aujourd’hui une solution très répandue. Ces bases de données permettent d’organiser, de stocker, de mettre à jour et d’interroger des données structurées volumineuses utilisées simultanément par différents programmes ou différents utilisateurs. Cela est impossible avec les représentations tabulaires étudiées en classe de première. Des systèmes de gestion de bases de données (SGBD) de très grande taille (de l’ordre du pétaoctet) sont au centre de nombreux dispositifs de collecte, de stockage et de production d’informations. L’accès aux données d’une base de données relationnelle s’effectue grâce à des requêtes d’interrogation et de mise à jour qui peuvent par exemple être rédigées dans le langage SQL (Structured Query Language). Les traitements peuvent conjuguer le recours au langage SQL et à un langage de programmation. Il convient de sensibiliser les élèves à un usage critique et responsable des données.
- Contenus : modèle relationnel : relation, attribut, domaine, clef primaire, clef étrangère, schéma relationnel.
- Capacités attendus: identifier les concepts définissant le modèle relationnel.
- Commentaires : ces concepts permettent d’exprimer les contraintes d’intégrité (domaine, relation et référence).
- Les tables vues en première
- La programmation orientée objet vue en terminale
Aspect historique
Le père des bases de données relationnelles est Edgar Frank Codd. Chercheur chez IBM à la fin des années
1960, il étudiait alors de nouvelles méthodes pour gérer de grandes quantités de données, car les
modèles et les logiciels de l'époque
ne le satisfaisaient pas. Mathématicien de formation, il était persuadé qu'il pourrait utiliser des
branches spécifiques des mathématiques (la théorie des ensembles et la logique des prédicats du premier
ordre) pour résoudre des difficultés
telles que la redondance des données, l'intégrité des données ou l'indépendance de la structure de la
base de données avec sa mise en œuvre physique.
En 1970, il publia un article où il proposait de
stocker des données hétérogènes dans
des tables, permettant d'établir des relations entre elles. De nos jours, ce modèle est extrêmement
répandu, mais en 1970, cette idée était considérée comme une curiosité intellectuelle. On doutait que
les tables puissent être jamais gérées
de manière efficace par un ordinateur.
Ce scepticisme n'a cependant pas empêché Codd de poursuivre ses
recherches. Un premier prototype de Système de gestion de bases de données relationnelles (SGBDR) a été
construit dans les laboratoires
d'IBM.
Depuis les années 80, cette technologie a mûri et a été adoptée par l'industrie. En 1987, le
langage SQL, qui étend l'algèbre relationnelle, a été standardisé. C'est dans ce type de modèle que se
situe ce cours de base de données.
En
savoir plus
Quelques définitions
De nombreuses activités ont besoin de stocker des informations. Vous avez de nombreux exemples autour de vous : le lycée et son ENT, les clubs, les jeux en ligne que vous utilisez, etc. Les informations doivent être disponibles pour certains, protégées, modifiables, indépendantes d'un point de vue matériel et logiciel, etc.
Une base de données stocke des informations en rapport avec une activité.
Ces
informations peuvent être de natures très hétérogènes.
Les informations sont structurées et cette structure permet
d'insérer, de supprimer, de mettre à jour et d'interroger les informations contenues.
Un SGBD (système de gestion de base de données) est une interface entre l'utilisateur et les données.
Voici deux exemples de SGBD : MySql et Oracle.
Conception d'une base de données relationnelle
Exemples de situations nécessitant des bases de données
Imaginez les situations développées dans les exemples ci-dessous :
Vous organisez un tournoi avec des joueurs. Les joueurs s'affrontent dans des duels. Vous voulez avoir des informations sur les joueurs, récupérer les scores, connaître les vainqueurs, etc.
Vous êtes cinéphile et vous voulez vous construire une base de données contenant des informations sur vos
films préférés : année de sortie, titre, genre, nom du réalisateur, etc.
Vous voulez également associer à
cette base des informations
sur les acteurs principaux.
Vous êtes passionné de séries et vous voulez construire une base de données qui contient des informations sur les hébergeurs, les séries, les acteurs et vos notations.
Imaginons le problème suivant : nous voulons construire une base de données contenant les élèves de seconde, première et de terminale pour les matières suivantes : physique, chimie, NSI, SNT, enseignement scientifique et mathématiques. Les élèves viennent de plusieurs lycées de l'académie. On veut stocker dans notre base de données des questions et/ou QCM.
On peut dans ce problème, s'intéresser à la phrase suivante : Galème GANBLAIN, élève de terminale F au lycée Saint-Exupéry, a passé le QCM intitulé "piles_files" dont les résultats sont stockés dans le fichier appelé "resultat_GANBLAIN.csv"
Cette phrase contient des informations qu'il va falloir structurer dans une base de données.
Pour concevoir une telle base de données, il va falloir respecter une démarche en étapes afin de définir les objets qui composent notre base de données ainsi que les relations entre ces objets.
La première approche de ces différents exemples serait une approche 'tableur'. Vous pouvez relire au passage le chapitre de première sur les tables : accès direct au chapitre table de première.
L'approche tableur pourrait être efficace sur un faible nombre de données mais notre base d'informations deviendrait vite instable ;
- redondance d'informations
- problème de suppression d'informations
- problème de cohérence dans les données : un nom écrit en chiffres, une score écrit avec des lettres, etc.
La modélisation de ces différents exemples se réalise en trois étapes principales qui correspondent à trois niveaux d'abstraction :
- Niveau conceptuel : description du projet en termes d'objets. Cette description est indépendante de tout support informatique. On parle de modèle entité-association. Les entités sont les objets de notre projet.
- Niveau logique : description des liens logiques entre les objets du projet. On parle dans ce cas de modèle relationnel.
- Niveau physique : implémentation informatique sur un SGBD.
Quelques éléments d'analyse de l'exemple traitant du QCM
Dans la phase de conception nous pouvons réaliser un tableau qui recense les données issues de notre analyse. Ce tableau correspond à l'analyse du côté matière.
| Concept/objet | Code/attribut | Description | type | Taille/domaine | Commentaire |
|---|---|---|---|---|---|
| Matière | idMatiere | Identifiant de la matière | Entier | La matière sera identifiée de manière unique par un nombre. Ce nombre sera appelé clé primaire. | |
| Matière | nomMatiere | Nom de la matière | Texte | 30 caractères | Physique, chimie, SNT, NSI, mathématiques, SI et enseignement scientifique |
| Niveau | idNiveau | Identifiant du niveau | Entier | Comme pour la matière, le niveau sera identifié par un nombre. | |
| Niveau | nomNiveau | Nom du Niveau | Texte | 30 caractères | Seconde, première, terminale, BTS_1, BTS 2 |
| Type de la question | idTypeQuestion | Identifiant du type de question | Entier | Le type de question sera identifié par un nombre. | |
| Type de la question | nomTypeQuestion | Nom du type de question | Texte | 30 caractères | QCM, exercice |
| Thème de la question | idTheme | Identifiant du thème | Entier | Le thème sera identifié par un nombre. | |
| Thème de la question | nomTheme | Nom du thème | Texte | 30 caractères | Structure de données, ihm, algo... |
| Description du thème de la question | desTheme | Description du thème | Texte | Texte qui décrit le thème |
Nous cherchons maintenant à décrire une question (exercice et/ou QCM). Pour écrire une question, il faut :
- Un nombre pour identifier la question de manière unique.
- Le type de question.
- Le niveau.
- La matière.
- Le thème.
- La question
- La réponse (ou les propositions de réponse dans le cadre d'un QCM)
- La solution (ou les solutions) dans le cadre d'un QCM
On traitera de manière particulière les champs niveau, matière et thème car ils existent déjà dans notre analyse. Il va falloir les relier à l'objet. Ce lien sera traité par un mécanisme que l'on appellera clé étrangère. Pour renseigner ces champs il suffira d'aller chercher les identifiants correspondants.
| Concept/objet | Code/attribut | Description | type | Taille/domaine | Commentaire |
|---|---|---|---|---|---|
| Question | idQuestion | Identifiant de la Question | Entier | La Question sera identifiée de manière unique par un nombre. Ce nombre sera appelé clé primaire. | |
| Question | idTypeQuestion | Identifiant du type de question | Entier | Ce nombre permet de relier le type de question à la question . Ce nombre sera appelé clé étrangère. | |
| Question | idNiveau | Identifiant du Niveau | Entier | Ce nombre permet de relier le niveau à la question . Ce nombre sera appelé clé étrangère. | |
| Question | idMatiere | Identifiant de la matière | Entier | Ce nombre permet de relier la matière à la question . Ce nombre sera appelé clé étrangère. | |
| Question | idTheme | Identifiant du thème | Entier | Ce nombre permet de relier le thème à la question . Ce nombre sera appelé clé étrangère. | |
| Question | Question | Question écrite en HTML | Texte | La question est écrite en langage HTML | |
| Question | reponse | Réponse écrite en HTML | Texte | La réponse est écrite en langage HTML | |
| Question | solution | La solution est une liste ou un tableau de vrai/faux |
Voici une représentation sous forme graphique de nos différents objets : 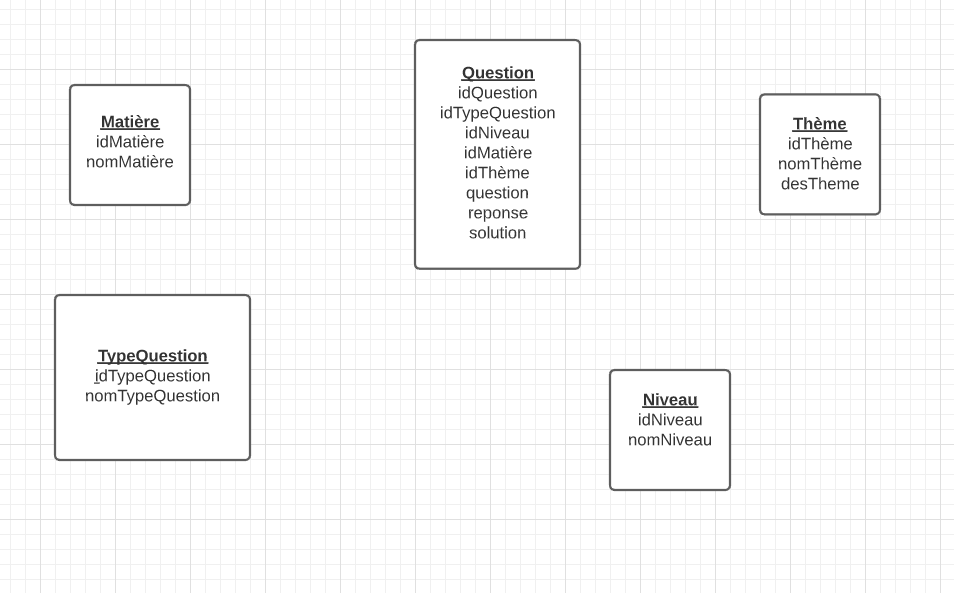
Indiquez sur le diagramme, ci-dessus, par une flèche les différents liens entre ces objets.
Une première analyse
Faire l'analyse d'une base de données dans laquelle vous voulez stocker :
-
Le nom d'une série à regarder.
-
Le réalisateur de cette série (Nom, prénom).
-
La date de sortie de cette série.
-
Le nombre de saisons.
-
L'âge légal à partir duquel on peut visionner la série.
-
La plateforme qui héberge cette série (nom).
-
Un descriptif de la série (texte bref).
Questions :
-
Quels objets peut-on mettre en évidence pour cette base de données que l'on pourrait appeler series ?
-
Établir un tableau de vos données.
-
Représenter vos données à l'aide d'une représentation du type de l'exercice précédent.
-
Établir les liens entre vos données.
Vous pouvez vous aider de ce type de graphique :
Vous pouvez utiliser l'outil yEd qui possède une version live et une version à installer. Cet outil vous servira pour les graphes et les arbres.
Vous pouvez utiliser différents logiciels pour modéliser vos bases de données, en voici un libre et gratuit : Accès au logiciel gratuit looping.
Entités, attributs et associations
Nous venons de mettre en évidence des objets et des relations entre ces objets. Il y a un certain nombre de notions à définir autour de ce concept de base de données relationnelles. Nous allons définir les notions de :
Attribut
Entité
Domaine
Identifiant/clé
Association
Une base de données relationnelle est la mise en action de toutes ces notions.
Entité, attribut, domaine
On appelle entité un objet unique qui peut être identifié distinctement par l'ensemble de ces attributs.
Dans la BDD "question", Matière ou Thème sont des entités.
Dans une BDD "élève du lycée", l'entité Élève est une entité.
Un attribut est une information élémentaire qui dépend de l'activité modélisée. Un attribut a un nom et une valeur typée.
idMatiere et nomMatiere sont des attributs de l'entité Matière.
La première est de type entier et la seconde de type chaîne de caractères.
Ainsi, l'attribut nomMatiere de type chaîne de caractères.
On appelle domaine d'un attribut l'ensemble des valeurs possibles que peut prendre un attribut.
Par exemple, le domaine de l'attribut nomMatiere est l'ensemble des chaînes de caractères : NSI, Maths, Français, Philo,....
De plus, le domaine de l'attribut idMatiere pourrait être les entiers de 20 à 40, celui de idThème les entiers de 41 à 100.
Autre exemple : le domaine de l'attribut DateNaissance d'un élève doit être l'ensemble des dates comprises entre deux valeurs choisies.
On appelle identifiant ou clé un attribut qui permet d'identifier de manière unique l'entité.
idMatiere est l'attribut correspondant au clé de l'entité Matière.
Autre exemple : idEleve est un nombre entier unique associé à chaque élève.
L'identifiant ou la clé sera appelée clé primaire quand on la considère dans la table qui lui est associée. idMatière est une clé primaire dans la table Matière alors qu'elle devient clé étrangère dans la table Question.
À quel concept (entité ou attribut ou identifiant/clé) pouvez-vous identifier une plaque immatriculation d'un véhicule ?
Une entité est souvent représentée sous la forme :
| Nom |
|---|
| identifiant |
| attribut |
| attribut |
| ... |
Dans notre projet, on définit une entité Eleve (On prendra comme convention de ne pas utiliser les accents). Cette entité possède plusieurs attributs :
- IdEleve (domaine : type entier)
- Nom (domaine : chaîne de caractères)
- Prenom (domaine : chaîne de caractères)
L'entité Eleve sera représentée de la manière suivante :
| Eleve |
|---|
| IdEleve |
| Nom |
| Prenom |
Quelques conventions d'écriture pour les entités et les attributs.
-
Le nom d'une entité, d'une association, d'un attribut doit être unique. Par exemple, il faut écrire comme attribut de l'entité
Eleve:nomEleveau lieu denom. -
Pour les
identifiants, il vaut mieux choisir un identifiant de type entier qui deviendra uneclé primairedans le schéma relationnel. Il vaut mieux éviter les identifiants de type chaîne de caractères ou composés de plusieurs attributs. -
Un attribut ne peut en aucun cas être partagé par plusieurs type entité.
-
Ne pas utiliser d'accents, ni de caractères particuliers.
-
Ne pas utiliser de mots réservés au langage d'interrogation et de manipulation des données (nous utiliserons SQL).
Une fois qu'une entité est définie, les occurrences de cette entité sont appelées instances ou enregistrements ou tuples ou n-uplets.
Eleve
- 3
- Beau
- Gosse
Une autre instance
Eleve
- 2
- Enfaillite
- Mélusine
On représente souvent ces tuples dans un tableau.
| IdELeve | Nom | Prenom |
|---|---|---|
| 3 | Beau | Gosse |
| 2 | Enfaillite | Mélusine |
| 1 | Térèz | Pascual |
Les attributs sont les noms se trouvant dans l'en-tête, la première ligne d'un tel tableau.
Les tuples ou enregistrements correspondent aux lignes suivantes d'un tel tableau.
Définir l'entité lycee. Quels sont ses attributs ? Penser à typer les attributs.
Définir l'entité Niveau.
Les associations
Une association définit un lien entre deux entités. Une association possède un nom et
éventuellement des attributs qui la caractérisent.
| Nom |
|---|
| attribut |
| attribut |
| ... |
- Un verbe pour caractériser une association.
- Un nom pour parler d'une entité.
Dans notre projet, nous avons les entités Eleve, Lycee et Niveau.
Nous pouvons définir l'association "scolariser".
En effet, un élève est scolarisé dans un établissement ainsi qu'un niveau. De plus, il a un numéro ou un nom de classe.
Cette association permet de relier les entités Eleve, Lycee et
Niveau
Cette association peut s'écrire :
-
Nom : scolariser
-
Attribut : nomClasse
Cette association est en lien avec les entités Eleve, Lycee et
Niveau. Ce lien sera effectif lors du passage au modèle relationnel. On parlera alors de
clés étrangères.
Voici une représentation de nos entités et de notre association : 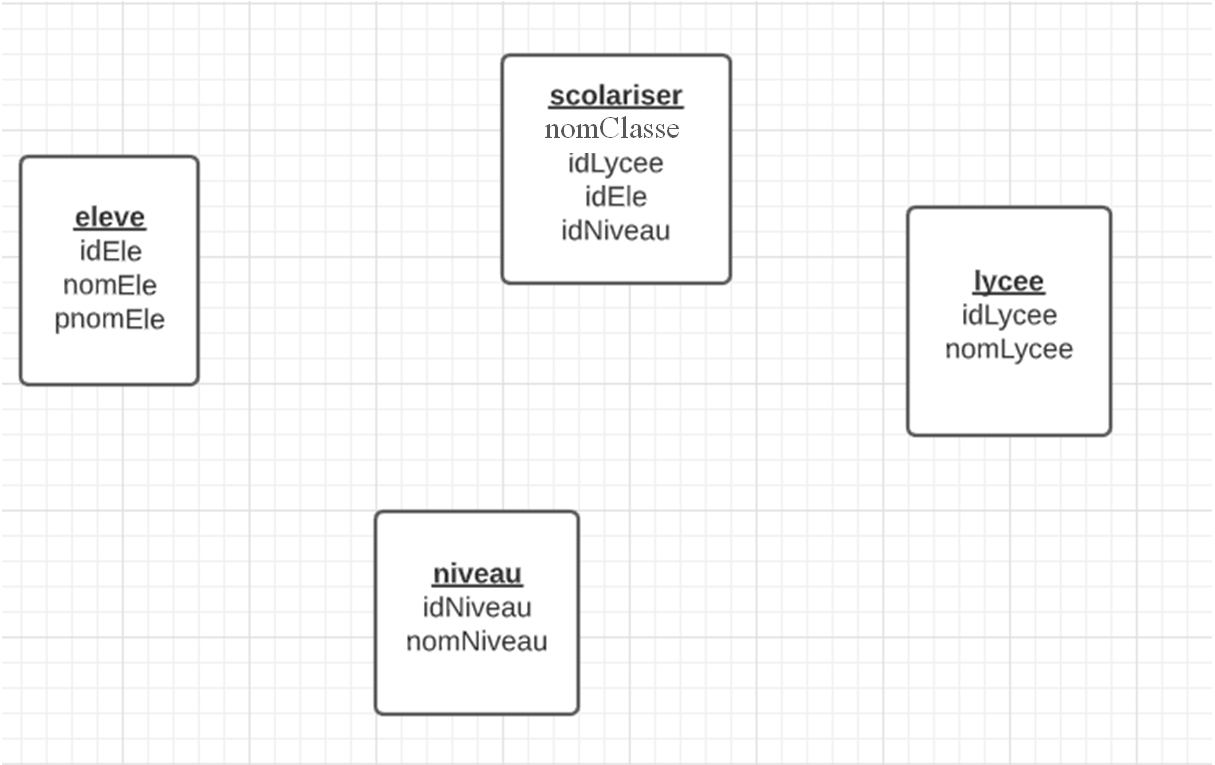
Établir les liens entre les entités et l'association scolariser.
Reprenez votre analyse de la base de données series.
Définir les entités avec leurs attributs
de la base de données series de l'exercice 2 à partir de vos
données.
-
Une base de données est un ensemble d'informations, souvent hétérogènes, qui sont structurées de telle sorte que l'insertion, la suppression et l'interrogation d'informations soient possibles.
-
Un Système de Gestion de Bases de Données (SGBD) est une interface entre un utilisateur et une base de données.
-
Une entité d'une base de données est un objet unique identifié par l'ensemble de ses attributs.
-
Un attribut est une information élémentaire liée à une entité portant un nom et une valeur typée.
-
Le domaine est l'ensemble des valeurs autorisées pour un attribut donné.
-
L'identifiant ou clef est un attribut permettant d'identifié de manière unique une entité.
-
Les enregistrements ou tuples sont les instances d'une entité.
-
Une association est une liaison entre deux entités. Elle possède un nom et éventuellement des attributs.
Schémas et modélisations
Il existe de nombreux schémas et différents types de modélisations qui ne sont pas toutes au programme de NSI.
Le modèle entité-association
Ce modèle est hors programme dans le cadre de NSI.
Le modèle relationnel
Une vidéo d'introduction au modèle relationnel
Dans le modèle relationnel, les entités et les associations sont transformés en tableaux. Ces tableaux sont
appelés relations.
On appelle relation un tableau à deux dimensions dans lequel les attributs correspondent aux colonnes et les $n$-uplets aux lignes.
Dans cet exemple, nous avons accès à une base de données Films qui est composée de plusieurs
entités et associations :
-
Une entité artiste
-
Une entité film
-
Une entité internaute
-
Une entité pays
-
Une association rôle
-
Une entité notation
Vision synthétique de la base de données : 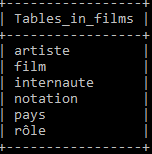
Voici quelques exemples de relations.
La relation artiste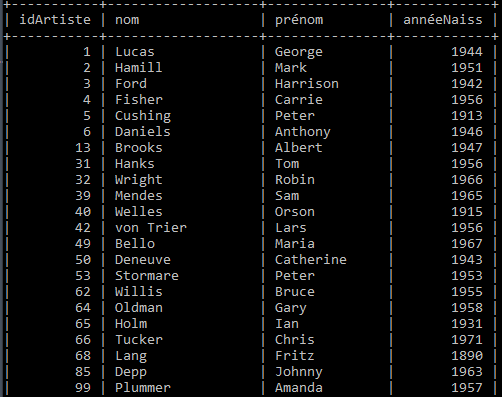
La relation rôle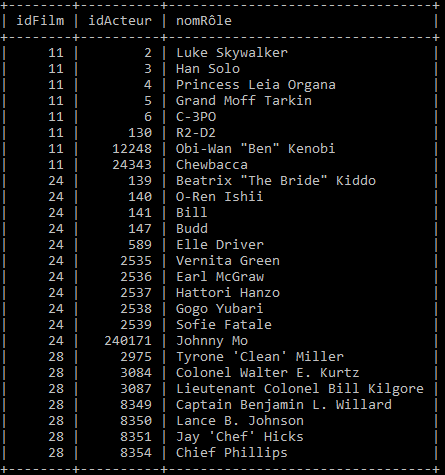
La relation film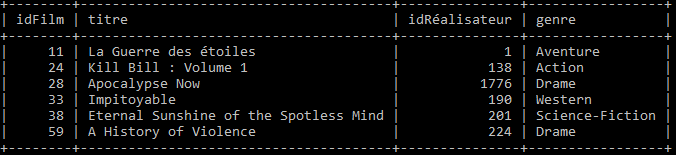
Dans la relation artiste ci-dessus :
- Quels sont les attributs ?
- Quel est l'identifiant ?
- Que pouvez-vous dire du type de données des attributs ?
- Citer une occurrence ($n$-uplet).
Dans la relation film ci-dessus :
- Quels sont les attributs ?
- Quel est l'identifiant ?
- Que pouvez-vous dire du type de données des attributs ?
- Citer une occurrence ($n$-uplet).
Dans l'association rôle ci-dessus :
- Quels sont les attributs ?
- Quel est l'identifiant ?
- Que pouvez-vous dire du type de données des attributs ?
- Citer une occurrence ($n$-uplet).
Observer dans les trois tables les correspondances entre les identifiants.
- Retrouver le nom de l'acteur qui joue le rôle de Luke Skywalker.
- Retrouver le nom du réalisateur du film "la guerre des étoiles".
- Quel rôle joue "Daniels Anthony"
Une clé primaire est un ensemble d'attributs dont les valeurs permettent de
distinguer les tuples les uns des autres.
Une clé primaire peut être simple ou composée (de plusieurs
attributs).
On utilise souvent un nombre entier (avec le préfixe id) pour prendre le rôle de clé primaire.
Dans la relation Eleve, la clé primaire est l'attribut idEleve,
attribut qui est bien de type entier.
Dans l'exemple sur la relation artiste :
-
Quel attribut est une clé primaire ?
-
Cette clé primaire est-elle simple ou composée ?
-
L'ensemble d'attributs (nom, prénom) peut-il être vu comme clé primaire pour cette relation ?
Une clé étrangère est un attribut qui est la clé primaire d'une autre relation. Elle est indiquée par (FK : "foreign key") ou précédée d'un #.
On retrouve les clés étrangères dans la transformation des associations en relations.
Reprenons notre exemple avec la base de données Eleve :
On s'intéresse à l'association scolariser. Cette association a des liens vers :
- l'entité
elevepar l'intermédiaire deidEle - l'entité
lyceepar l'intermédiaire deidLycee - ...
idEle, idLycee sont des clés étrangères
dans l'association scolariser.
Quelle est la troisième clé étrangère de l'association scolariser de l'exemple ci-dessus ?
Vers quelle entité établit-elle la
liaison ?
Un schéma relationnel d'une relation est la donnée pour cette relation :
-
d'un nom,
-
de l'ensemble des attributs en précisant leur domaine propre,
-
de (ou des) l'attribut servant de clé primaire et des attributs étant éventuellement des clés étrangères.
Un tel schéma relationnel peut être écrit sous la forme d'un tableau ou sous forme textuelle.
On peut transformer une entité en relation donnée par son schéma relationnel.
-
Les attributs de l’entité deviennent les attributs du schéma relationnel (de même nom que l’entité).
-
L’identifiant devient clé primaire.
-
Dans un schéma relationnel la clé primaire est mise en évidence soit avec l'indication CP (ou PK pour Primary Key), soit en étant soulignée, soit avec le dessin d'une clé, soit indiquée à l'aide d'une remarque.
On peut transformer en relation donnée par son
schéma relationnel, l'entitéEleve.
| Eleve |
|---|
| IdEleve |
| Nom |
| Prenom |
| Eleve |
|---|
| (CP)IdEleve |
| Nom |
| Prenom |
On peut également retrouver une notation textuelle où la clé primaire est soulignée : Eleve(IdEleve, Nom, Prenom)
Dans un schéma relationnel, une clé étrangère est mise en évidence soit avec l'indication FK (pour Foreign Key), soit en étant précédée d'un #.
| scolariser |
|---|
| nomClasse |
| scolariser |
|---|
| (FK)idLycee |
| (FK)idEleve |
| (FK)idNiveau |
| nomClasse |
En notation textuelle où les clés étrangères sont précédées d'un symbole # : scolariser(#idLycee, #idEleve, #idNiveau, nomClasse)
La relation scolariser étant une association ne possède pas de clé primaire.
Une base de données relationnelle est un ensemble de relations.
L'ensemble des schémas relationnels appelé schéma de la base de données.
Vous verrez parfois le mot relation utilisé à la place de schéma relationnel.
Vous cherchez à modéliser un annuaire téléphonique.
Établir le schéma de la base de données d'un tel
annuaire. Vous pouvez faire simple en écrivant une seule relation dans laquelle le numéro de téléphone
devient clé primaire. Vous pouvez également
compliquer un peu les choses en écrivant deux relations : une pour les personnes et une autre pour les
numéros. Il faudra dans ce cas utiliser une clé étrangère pour relier ces deux tables.
Établir le schéma relationnel de la base de données series travaillée depuis l'exercice 2.
Les contraintes d'intégrité
Il existe un certain nombres de règles à respecter pour respecter l'intégrité d'une base de données. Ces règles visent à préserver la cohérence des données et garantir une stabilité de notre base dans le temps.
Il existe des catégories de contraintes d'intégrité à respecter :
- contrainte d'entité
- contrainte de domaine
- contrainte de référence
- contraintes d'utilisateurs
Contrainte d'entité
L'existence et l'unicité des clés primaires : une clé primaire ne peut être vide et il ne peut y avoir de doublons dans une relation. Toute relation doit posséder une clé unique que l'on appelle clé primaire. Cela définit la contrainte d'entité (appelée aussi contrainte de relation).
Le problème typique est l'utilisation de l'attribut nomEle dans notre entité Eleve.
Cet attribut ne peut définir de manière unique un élève car plusieurs élèves peuvent avoir le même nom.
Nous ne pouvons donc pas utiliser
cet attribut comme clé primaire. Dans notre exemple nous avons utilisé un attribut idEle.
Chaque élève est donc identifié par un numéro unique (unicité); de plus, chaque a nécessairement un tel numéro
d'identification (existence).
Contrainte de domaine
Les données que nous souhaitons stocker dans notre base de données ont des formats différents. On parle alors
de domaine. On peut s'inspirer des types de données des langages de programmation que nous
avons étudiés (integer, booléens,
float, char, string).
Les contraintes de domaines doivent permettre de :
-
représenter les données sans perte d'information,
-
d'éviter les erreurs de saisies.
Tout attribut d'un n-uplet doit prendre une valeur appartenant à l'ensemble des valeurs possibles prédéfinies pour cet attribut : on parle de contrainte de domaine.
La relation Eleve(IdEleve, Nom, Prenom) a trois attributs :
-
L'attribut IdEleve est nécessairement un entier,
-
Les attributs Nom et Prenom sont nécessairement des chaînes de caractères.
Ainsi, le n-uplet (3, "Beau", "Gosse") peut être un tuple de la relation Eleve.
Par contre, ("trois", "Go", "Boss") ne peut pas être un tuple de la relation Eleve
car "trois" n'est pas un nombre entier.
-
On peut inventer ses propres domaines de données, mais souvent on utilise des domaines prédéfinis dans le logiciel d'implémentation de notre base.
-
Lorsque les contraintes de domaines deviennent sophistiquées, on parle alors de
contraintes utilisateurs:-
on veut qu'une donnée soit un élément d'une liste (liste des lycées par exemple),
-
on veut qu'une donnée numérique soit bornée (âge d'un personne),
-
on veut qu'une donnée possède un nombre de caractères défini à l'avance (code postal),
- ...
-
-
Les logiciels d'implémentation proposent des solutions à ce type de contraintes.
Contrainte de référence
Nous utilisons les clés primaires afin de distinguer de manière unique nos entités. Ces clés primaires servent également de références dans les autres relations. Il faut veiller à ce que les références soient effectives. On ne peut pas définir une entité qui fait référence par une clé étrangère à une entité qui n'existe pas.
La valeur d'un attribut qui est une clé étrangère doit nécessairement faire référence à un n-uplet existant dans la relation dont cette clé étrangère est la clé primaire : on parle de contrainte de référence.
Reprenons notre relation scolariser : scolariser(#idLycee, #idEleve,
#idNiveau, nomClasse)
Dans cette relation : idLycee, idEleve, idNiveau sont des clés étrangères. On ne peut scolariser que des
élèves connus dans des lycées connus sur des niveaux connus. Pour ajouter une nouvelle scolarisation d'un
élève fictif, il faudra que l'élève
soit existant, que son lycée soit existant et que sa classe soit connue. Il sera également impossible de
supprimer les entités Lycee ou Eleve
On propose un tableau qui donne les occurrences d'une relation Joueur définie par le schéma relationnel : Joueur(IdJoueur,nomJoueur,pNomJoueur,dNaissanceJoueur)
| IdJoueur | nomJoueur | pNomJoueur | dNaissanceJoueur |
|---|---|---|---|
| 1 | Terez | Pascual | 124 |
| 1 | Gosse | 452 | |
| 4 | Terez | Pascual | 124 |
Repérez les anomalies dans ces occurrences. Quelles sont les contraintes non respectées et/ou à mettre en œuvre ?
-
Une relation est un tableau à deux dimensions dans lequel les attributs sont les colonnes et les tuples ou enregistrements sont les lignes.
-
Une clef primaire est un ensemble d'attributs non vide qui permet d'identifier de manière unique une relation.
-
Une clef étrangère d'une relation est un attribut étant aussi la clé primaire d'une autre relation.
-
Un schéma relationnel d'une relation est un ensemble formé du nom de la relation, de ses attributs en précisant le domaine et les clef primaire et éventuellement étrangères.
-
Une clé primaire est reconnaissable soit par un soulignement, soit par une dessin de clé, soit par les lettres CP ou PK.
-
Une clé primaire peut être simple (définie par un seul attribut) ou composée (définie par un ensemble de plusieurs attributs)
-
Une clé étrangère est reconnaissable soit par le symbole #, soit par les lettres FK.
-
La contrainte d'entité ou contrainte de relation est le fait que toute relation doit avoir une clé primaire unique.
-
La contrainte de domaine est le fait que tout attribut d'enregistrement doit prendre ses valeurs dans un ensemble de valeurs possibles précis.
-
La contrainte de référence est le fait que toute valeur de clé étrangère doit faire référence à un enregistrement existant dans la relation dont cette clef étrangère est la clef primaire.
Exercices sur le modèle relationnel
Voici comment le logiciel phpMyadmin représente les bases de données :
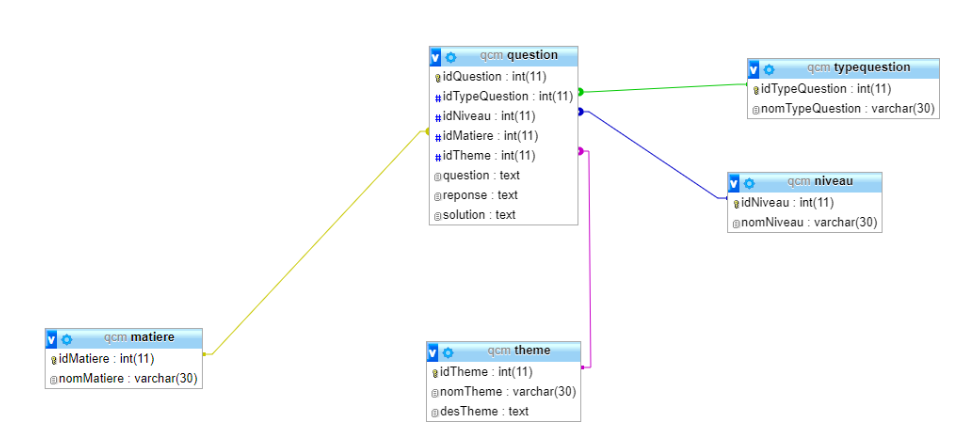
-
Repérez les différentes entités et/ou associations.
-
Repérez les clés primaires et les clés étrangères de la relation question.
-
Repérez les domaines des différents attributs de cette relation question. En faisant l'analogie avec vos connaissances sur les langages de programmation, donnez les différents types.
En utilisant la représentation du logiciel :
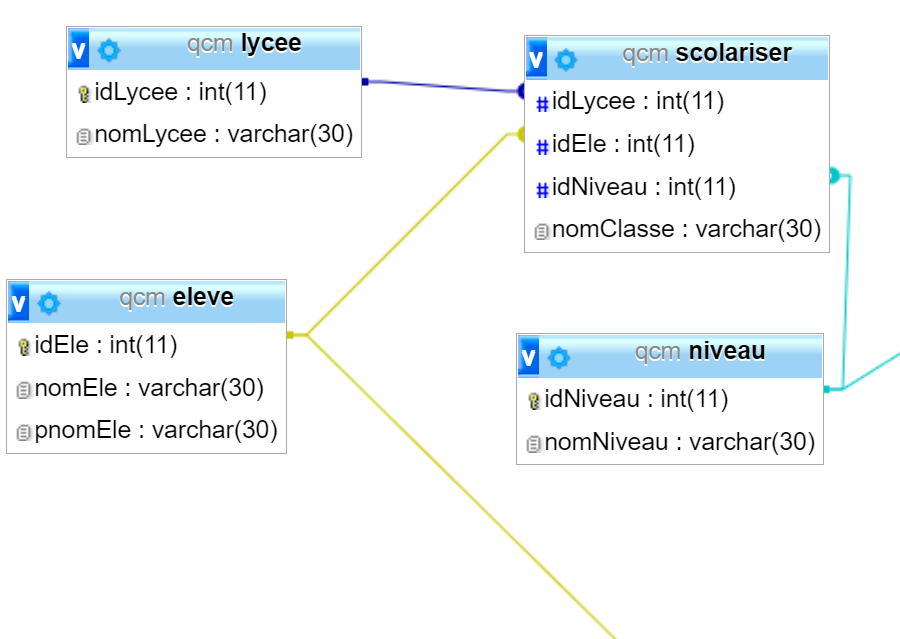
Établir les schémas relationnels des entités et/ou associations présentées.
Vous pouvez réfléchir à une base de données qui donnera naissance à un mini-projet.
-
Une analyse du projet avec une brève description.
-
Un minimum de quatre entités.
-
Un minimum de deux associations.
Exercices de renforcement
clefs primaire et étrangères
Une restauratrice a mis en place un site Web pour gérer ses réservations en ligne. Chaque
client peut s’inscrire en saisissant ses identifiants. Une fois connecté, il peut effectuer une
réservation en renseignant le jour et l’heure. Il peut également commander son menu en ligne
et écrire un avis sur le restaurant.
Le gestionnaire du site Web a créé une base de données associée au site nommée restaurant,
contenant les quatre relations du schéma relationnel ci-dessous :
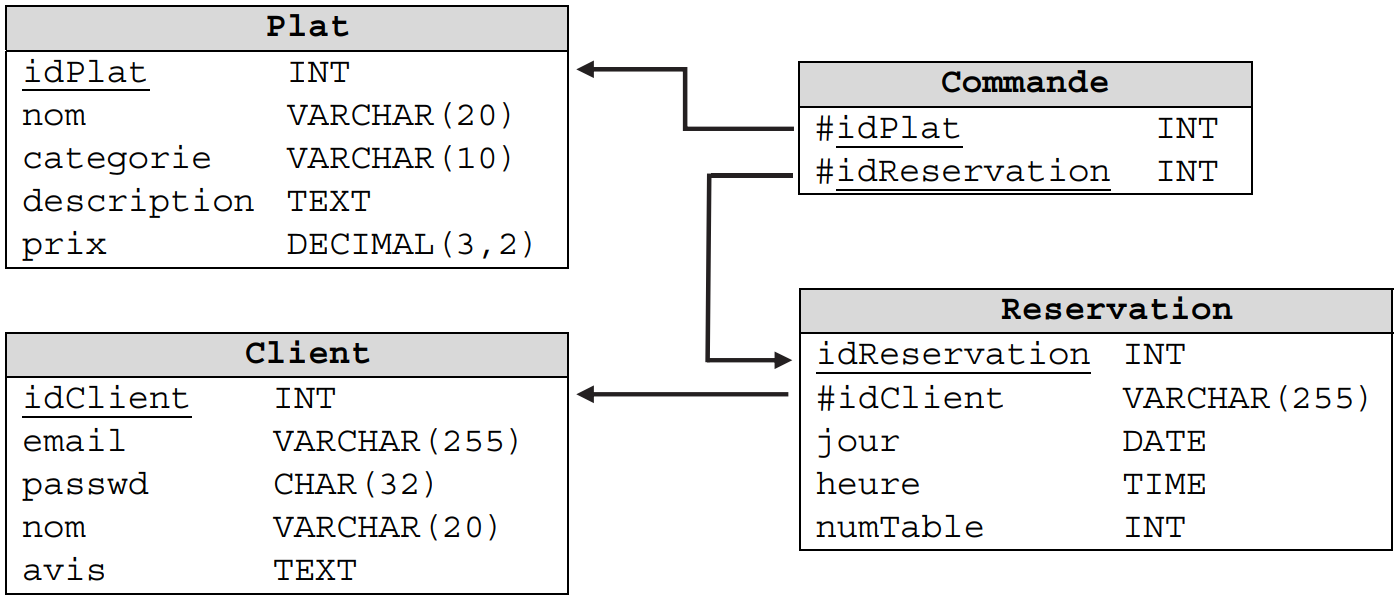
-
-
Quelle est la clef primaire de la relation
Plat? -
Cette clé primaire est-elle simple ou composée ?
-
Quel est le domaine de cette clef ?
-
-
-
Quelle est la clef primaire de la relation
Commande? -
Cette clé primaire est-elle simple ou composée ?
-
-
-
L'attribut
idClientpeut-il être la clé primaire de la relationReservation? Pourquoi ? -
Le couple
passwd, nompeut-il être la clé primaire de la relationClient? Pourquoi ?
-
-
-
La clef primaire de la relation
Platest l'attribut soulignéidPlat. -
Cette clé primaire est simple car elle est constituée d'un seul attribut.
-
Le domaine de l'attribut
idPlatest le type entier.
-
-
-
La clef primaire de la relation
Commandeest le couple d'attributs soulignésidPlat, idReservation -
Cette clé primaire est composée car elle est constituée de plusieurs attributs.
-
-
-
L'attribut
idClientne peut pas être la clé primaire de la relationReservationcar cet attribut n'est pas différent pour chaque réservation : un même client peut effectuer plusieurs réservations. -
Le couple
passwd, nomne peut pas être la clé primaire de la relationClientcar il ne permet pas d'identifier de manière unique un client. Deux clients différents peuvent porter le même nom et avoir choisi par hasard le même mot de passe, quand bien même la probabilité de cela soit très faible.
-
Une restauratrice a mis en place un site Web pour gérer ses réservations en ligne. Chaque
client peut s’inscrire en saisissant ses identifiants. Une fois connecté, il peut effectuer une
réservation en renseignant le jour et l’heure. Il peut également commander son menu en ligne
et écrire un avis sur le restaurant.
Le gestionnaire du site Web a créé une base de données associée au site nommée restaurant,
contenant les quatre relations du schéma relationnel ci-dessous :
-
Quelles relations admettent des clefs étrangères ?
-
Quelle est la clef étrangère de la relation
Reservation? -
Vers quelle relation cette étrangère établit-elle une liaison ?
-
Quel est le domaine de cette clef ?
-
Combien de clefs étrangères apparaissent dans la relation
Commande?
-
Les relations
ReservationetCommandeadmettent des clefs étrangères, ce sont les attributs matérialisés par le symbole #. -
La clef étrangère de la relation
Reservationest l'attributidClient. -
La clef étrangère
idClientétablit une liaison vers la relationClient. -
Le domaine de la clef étrangère
idClientest une chaîne de caractères (d'après le type VARCHAR). -
Deux clefs étrangères apparaissent dans la relation
Commande:idPlatetidReservation.
Schéma relationnel
Vous créez un jeu vidéo en ligne. Vous voulez gérer les comptes des joueurs avec une base de données.
Cette base de données contient plusieurs entités :
-
Une entité
Joueurqui contient le nom, le mot de passe, le statut du joueur et le héros joué en ligne. -
Une entité
statutqui permet de savoir si le joueur a un compte premium ou nom grâce à un attribut de type booléen. -
Une entité
Herosqui permet de savoir le type de héros choisi, son niveau d'expérience, son nom choisi par le joueur.
Établir le schéma relationnel de cette base de données en précisant le type (INT, STRING ou BOOLEAN) de chaque attribut.
Cliquer pour afficher la solutionVoici le schéma relationnel de la base de données :
-
L'entité
Joueurest modélisée par la relation Joueur(idJoueur:INT,nomJoueur:STRING ,password:STRING,#idStatut:INT,#idHeros:INT). -
L'entité
Statutest modélisée par la relation Statut(idStatut:INT,premium:BOOLEAN). -
L'entité
Herosest modélisée par la relation Heros(idHeros:INT,typeHeros:STRING, nivExpHeros:INT,nomHeros:STRING).
Contraintes d'intégrité
Vous avez créé un jeu en ligne et vous gérez le compte des joueurs inscrits par l'intermédiaire d'une base de données.
Suite à une tentative d'attaque informatique, votre base de données a peut-être été corrompue.
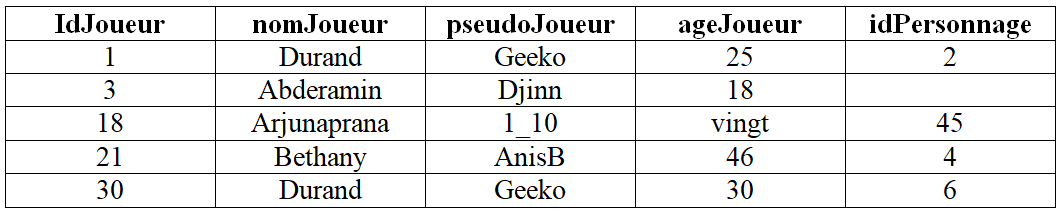
Pour le savoir vous étudiez des extraits des cinq relations définissant votre base de données :
-
Joueur(IdJoueur:INT,nomJoueur:STRING,pseudoJoueur:STRING,ageJoueur:INT,#idPersonnage:INT),
-
Personnage(IdPersonnage:INT,nomPersonnage:STRING,typePersonnage:STRING,experiencePersonnage:INT,#idArme:INT,#idVisuel:INT),
-
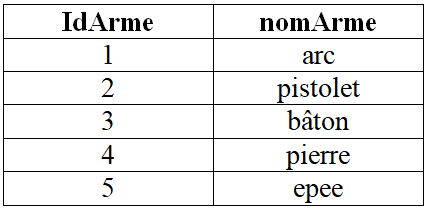
Arme(IdArme:INT,nomArme:STRING),
-
Visuel(IdVisuel:INT,#idGenre:INT,typeVisuel:STRING).
-
Genre(IdGenre:INT,nomGenre:STRING).
Voici :
-
un extrait de la relation Joueur qui représente les cinq premières lignes de la table ordonnée par ordre croissant des valeurs de l'attribut idJoueur :
-
un extrait de la relation Personnage qui représente les cinq premières lignes de la table ordonnée par ordre croissant des valeurs de l'attribut idPersonnage :

-
un extrait de la relation Arme qui représente les cinq premières lignes de la table ordonnée par ordre croissant des valeurs de l'attribut idArme :
-
un extrait de la relation Visuel qui représente les cinq premières lignes de la table ordonnée par ordre croissant des valeurs de l'attribut idVisuel :
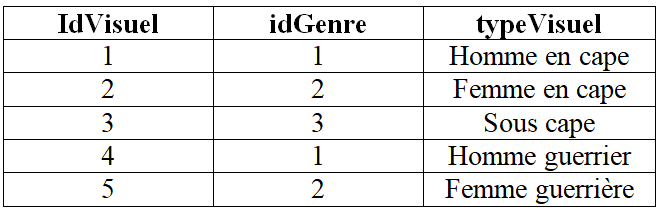
-
la relation Genre :

Repérez-vous des anomalies dans ces tables ? Si oui, quelles contraintes ne sont pas respectées ?
Cliquer pour afficher la solution-
À la deuxième ligne de la table Joueur manque la référence idPersonnage : la contrainte de référence n'est pas respectée.
-
À la troisième ligne de la table Joueur l'âge n'est pas de type entier : la contrainte de domaine n'est pas respectée.
-
À la quatrième ligne de la table Joueur la référence 4 de la clé étrangère idPersonnage correspond à aucune valeur de la clé primaire idPersonnage de la table Personnage (puisque les n-uplets sont rangés dans l'ordre croissant des valeurs de idPersonnage) : la contrainte de référence n'est pas respectée.
-
Les quatrième et cinquième ligne de la table Personnage sont identifiées par la même valeur de la clé primaire idPersonnage : la contrainte d'entité (ou de relation) n'est pas respectée.
Logiciels pour représenter les relations
Il existe des logiciels pour représenter les relations et les entités et les associations.
"test d'alignement"
Bibliographie et sitographie
- "Numérique et sciences informatiques" - "Compétences attendues" - ellipses -
- "Numérique et sciences informatiques" - "24 leçons avec exercices corrigés"- Thibaut Balabonski - Sylvain Conchon - Jean-Christophe Filliâtre - Kim Nguyen- ellipses -
- "Numérique et sciences informatiques" - "Prépas sciences" - Serge Bays - ellipses -
Savoir et Savoir faire
- Repérer la clef primaire et celles étrangères d'une relation dont est donné le schéma relationnel.
- Transformer une entité ou une association en schéma relationnel
- Trouver des anomalies dans des tables de base de données.
- Connaître les concepts du modèle relationnel : relation, attribut, domaine, clef primaire, clef étrangère, schéma relationnel.
- Connaître les différentes contraintes d'intégrité.

Les différents
auteurs mettent l'ensemble du site à disposition selon les termes de la licence Creative
Commons Attribution - Pas d’Utilisation Commerciale - Partage dans les Mêmes Conditions 4.0
International